LLM Configs¶
Verbinden und konfigurieren Sie Sprachmodelle von beliebten Anbietern oder Ihre benutzerdefinierten KI-Anwendungen für umfassende Tests
Übersicht¶
elluminate bietet einige LLM Modelle, die standardmäßig konfiguriert sind, und ermöglicht es Ihnen, beliebige weitere Sprachmodelle mit Ihren Projekten zu verbinden - von beliebten Anbietern wie OpenAI bis hin zu Ihren eigenen benutzerdefinierten KI-Anwendungen. Diese Flexibilität ermöglicht es Ihnen, Prompts über verschiedene Modelle hinweg zu testen, Ihre bereitgestellten KI-Systeme zu überwachen und für Kosten und Leistung zu optimieren.
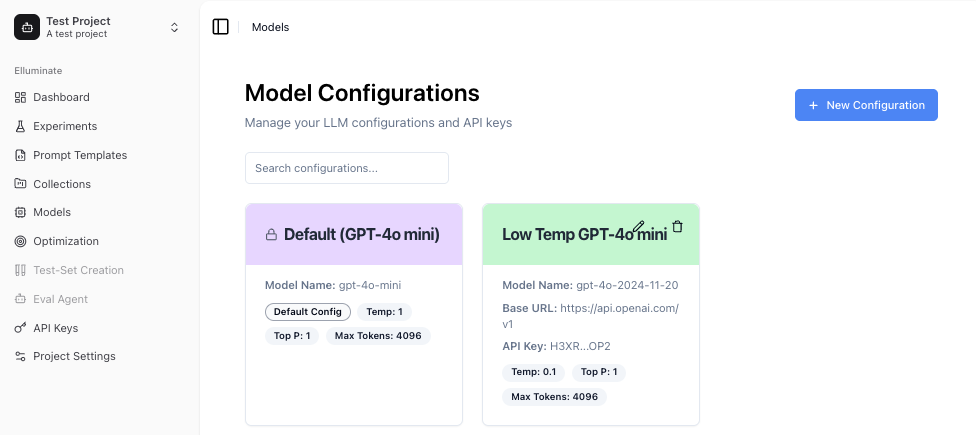
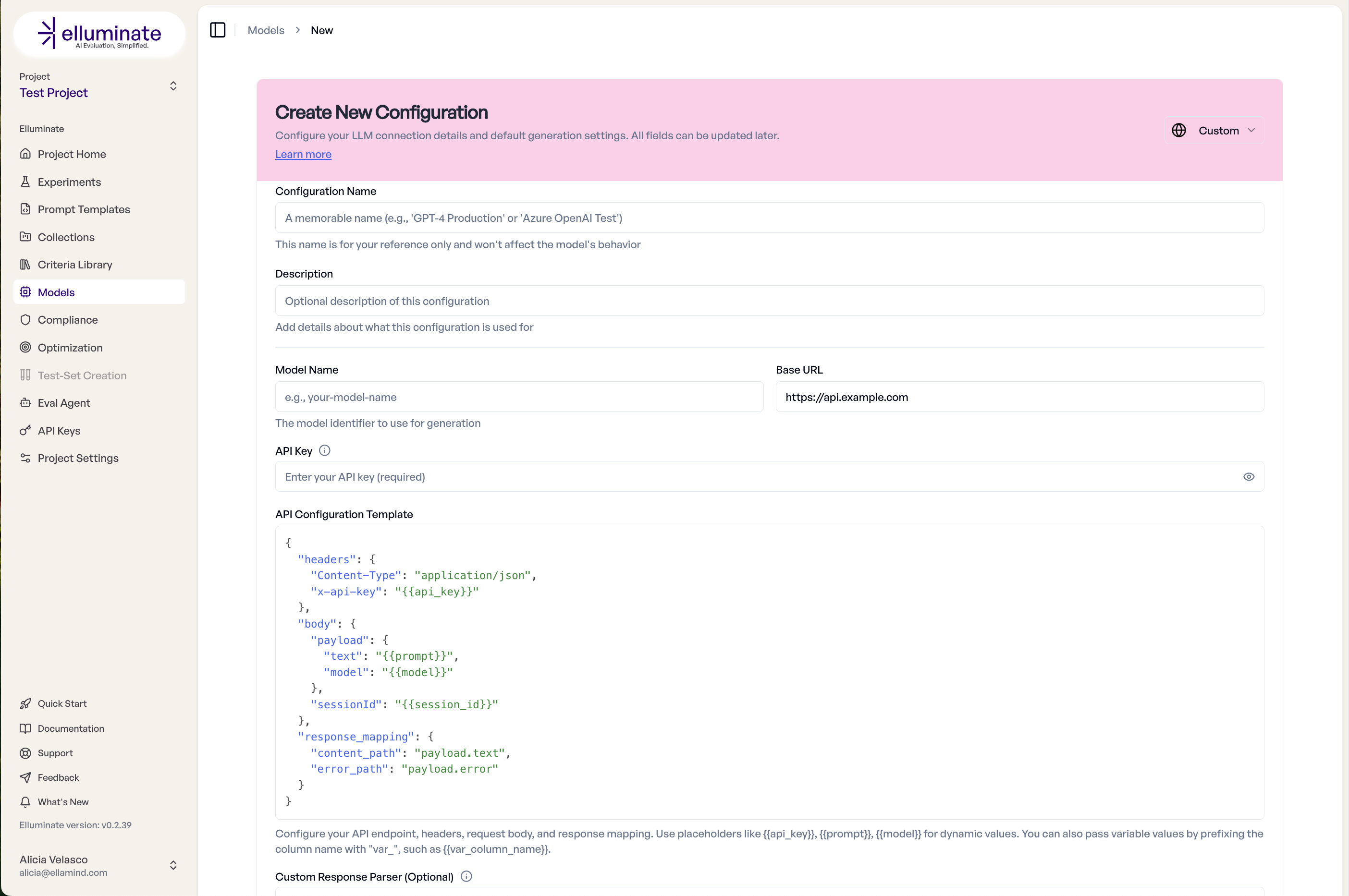
Neue Konfiguration erstellen¶
Das Erstellen einer neuen Konfiguration ermöglicht es Ihnen, mehrere Parameter des LLM zu modifizieren. Die häufigsten sind temperature und Top p, die die Zufälligkeit und Vielfalt der Modellausgabe steuern. Für eine Standardkonfiguration können Sie die Standardwerte des Anbieters verwenden, indem Sie das Kontrollkästchen anklicken.
Max tokens und Max Connections Steuerungen helfen Ihnen, die Länge der Antworten sowie die Anzahl der gleichzeitig möglichen Anfragen für jede Modellkonfiguration zu begrenzen.
Für einige der neueren Modelle können Sie auch den Reasoning Effort modifizieren.
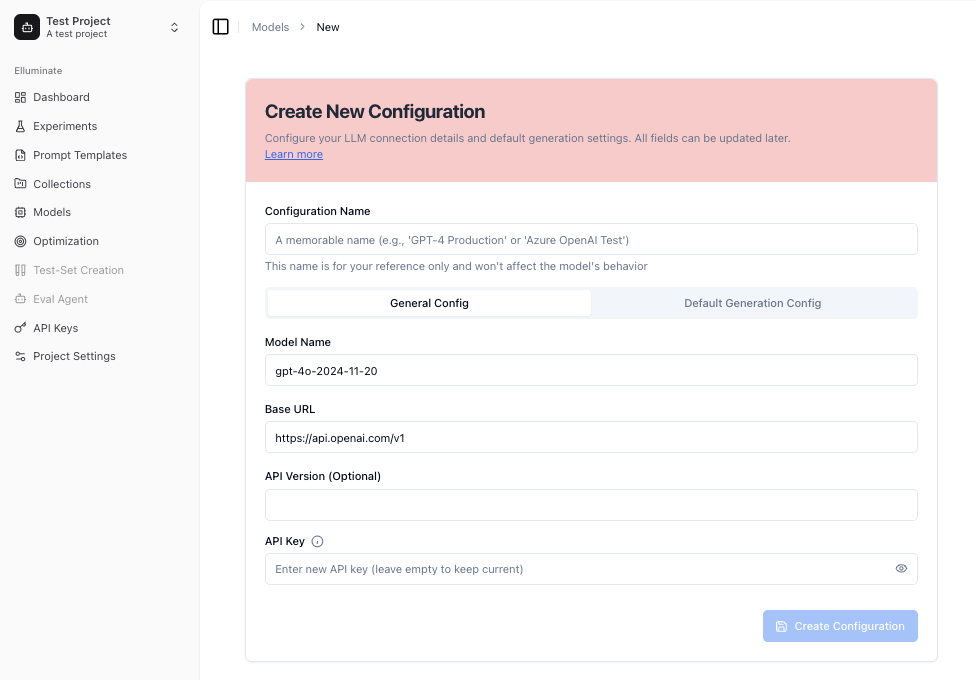
Die Verwendung einer anderen Base URL und API Key leitet Ihre Verbindung über Ihren bevorzugten Pfad.
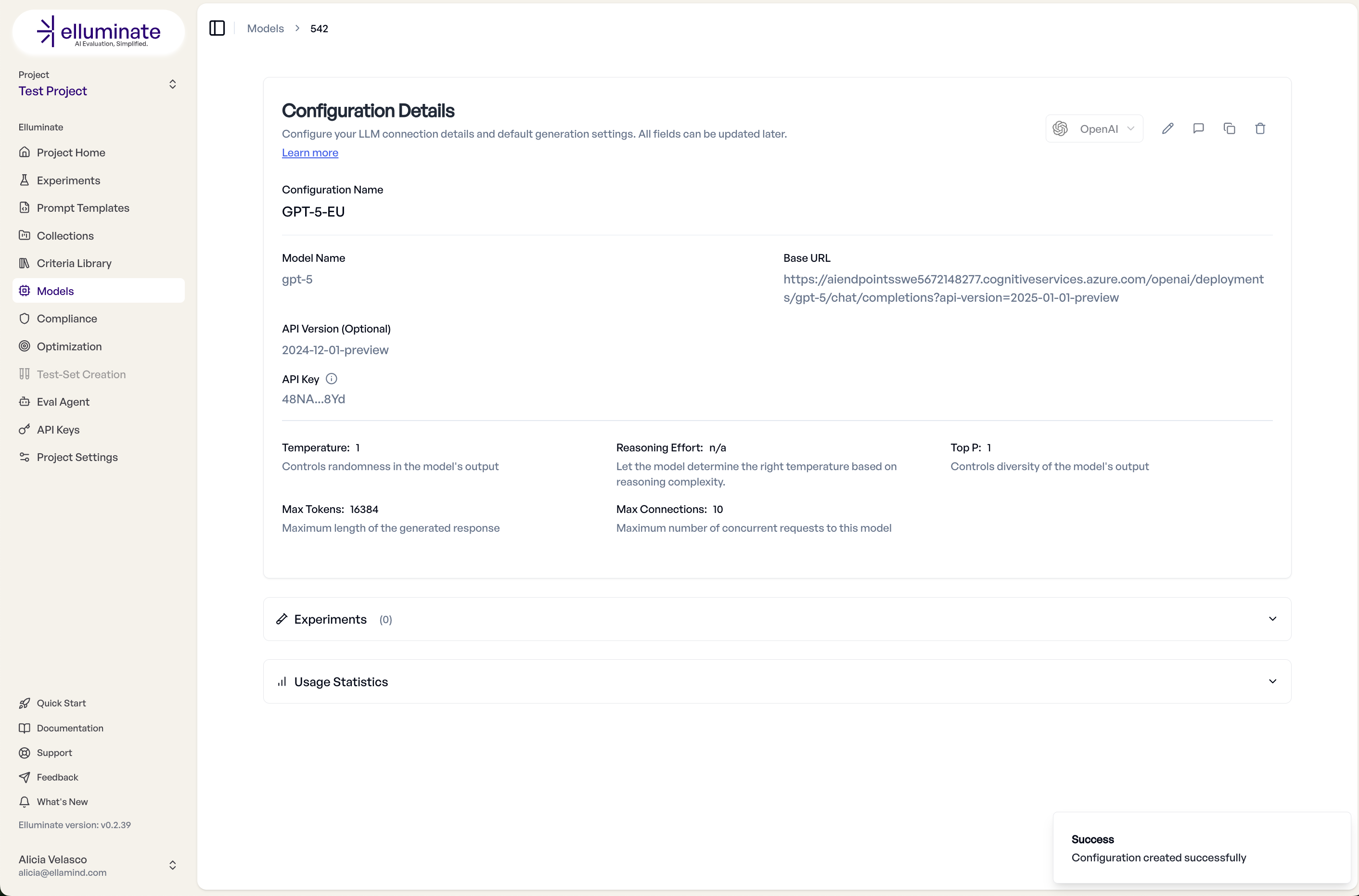
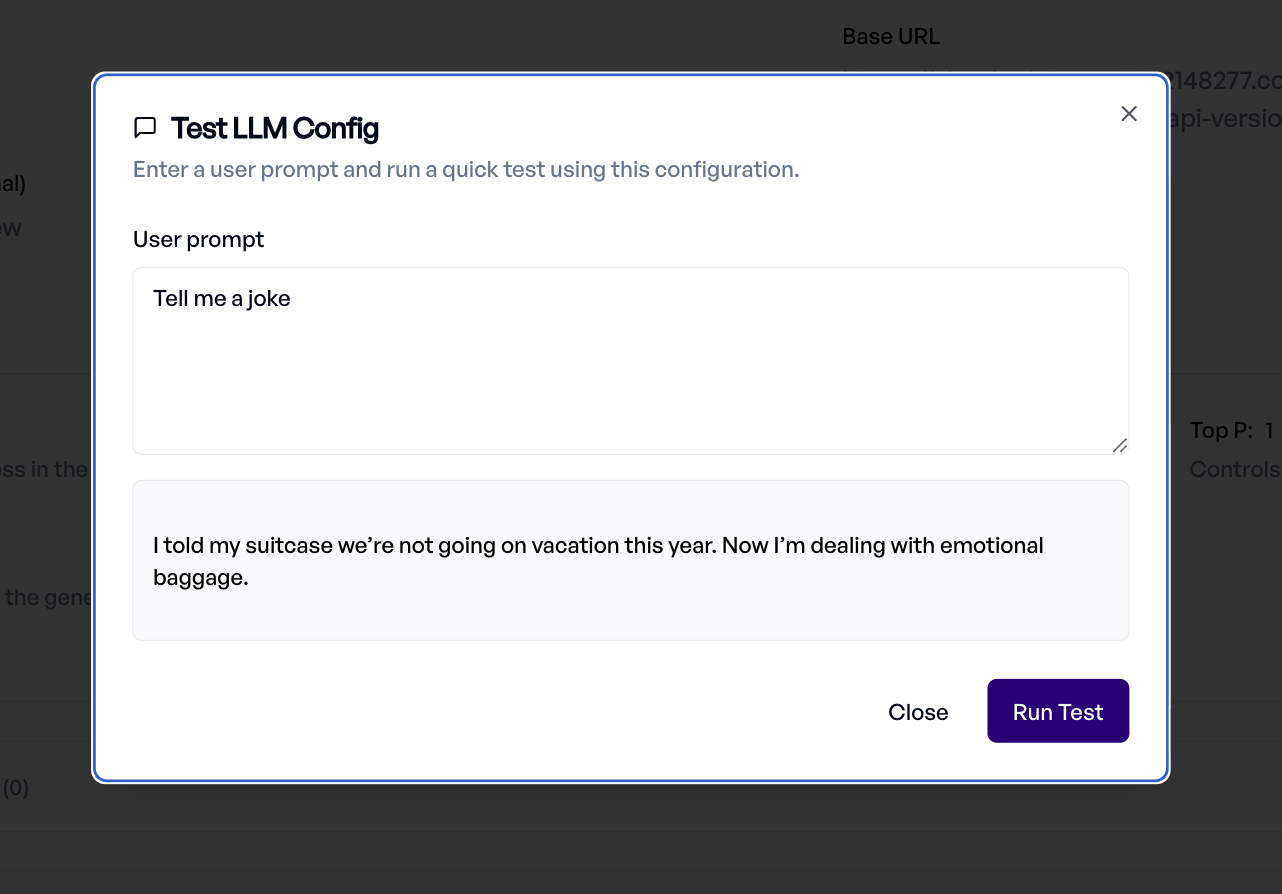
Sobald die neue Konfiguration bereit ist, können Sie sie direkt vom selben Bildschirm aus mit dem Konfiguration testen Button testen.
Benutzerdefinierte API-Endpunkte¶
Der Custom API Endpoint ermöglicht es Ihnen, den Zugriff auf Ihre KI-Anwendung mit Headers, Request Body und Response Mapping zu konfigurieren. Sobald konfiguriert, kann Ihr benutzerdefiniertes Modell in jedem Experiment innerhalb des Projekts verwendet werden.
SDK-Anleitung für LLM-Konfiguration¶
Umgebungsbasierte Konfiguration¶
# Load from environment
config = client.llm_configs.create(
name="Production GPT",
llm_model_name="gpt-4o",
api_key=os.getenv("OPENAI_API_KEY"), # From .env file
inference_type="openai"
)
Konfiguration von Leistungsparametern¶
performance_config = client.llm_configs.create(
name="Fast Response Model",
llm_model_name="gpt-4o-mini",
api_key="key",
inference_type="openai",
# Performance settings
max_tokens=500, # Limit response length
temperature=0.3, # More deterministic
top_p=0.9, # Nucleus sampling
max_connections=20, # Parallel requests
timeout=10, # Fast timeout in seconds
max_retries=2, # Limited retries
description="Optimized for quick responses"
)
Grundlegende Custom API-Einrichtung¶
Für eine einfache REST API, die Prompts akzeptiert und Antworten zurückgibt:
custom_config = client.llm_configs.create(
name="My Custom Model v2",
llm_model_name="custom-model-v2",
api_key="your-api-key",
llm_base_url="https://api.mycompany.com/v1",
inference_type="custom_api",
custom_api_config={
"headers": {
"Authorization": "Bearer {{api_key}}",
"Content-Type": "application/json",
"X-Model-Version": "{{model}}"
},
"body": {
"prompt": "{{prompt}}",
"max_tokens": 1000,
"temperature": 0.7,
"stream": False
},
"response_mapping": {
"content_path": "data.response",
"error_path": "error.message"
}
},
description="Our production recommendation model"
)
Fortgeschrittene Custom API mit Template-Variablen¶
Übergeben Sie Template-Variablen aus Ihren Collections direkt an Ihre API:
advanced_config = client.llm_configs.create(
name="Context-Aware Assistant",
llm_model_name="assistant-v3",
api_key="secret-key",
llm_base_url="https://ai.internal.com",
inference_type="custom_api",
custom_api_config={
"headers": {
"X-API-Key": "{{api_key}}",
"Content-Type": "application/json"
},
"body": {
"query": "{{prompt}}",
"context": {
"user_id": "{{var_user_id}}", # From template variables
"session_id": "{{var_session_id}}",
"category": "{{var_category}}",
"history": "{{var_conversation_history}}"
},
"config": {
"model": "{{model}}",
"temperature": 0.5,
"max_length": 2000
}
},
"response_mapping": {
"content_path": "result.text",
"error_path": "status.error_message"
}
}
)
Für APIs, die Multi-Turn-Konversationen unterstützen, verwenden Sie den {{messages}} Platzhalter, um das vollständige Konversations-Array zu übergeben:
multiturn_config = client.llm_configs.create(
name="Multi-Turn Assistant",
llm_model_name="chat-model",
api_key="your-api-key",
llm_base_url="https://api.example.com/chat",
inference_type="custom_api",
custom_api_config={
"headers": {
"X-API-Key": "{{api_key}}",
"Content-Type": "application/json"
},
"body": {
"conversation": {
"turns": "{{messages}}" # Vollständiges Nachrichten-Array
},
"model": "{{model}}"
},
"response_mapping": {
"content_path": "response.text"
}
}
)
Der {{messages}} Platzhalter enthält alle Nachrichten (System, User, Assistant) aus der Konversation. Wenn er als reiner Platzhalter verwendet wird (z.B. "{{messages}}"), bleibt die Listenstruktur im Request-Body erhalten. Der {{prompt}} Platzhalter bleibt für Einzelnachrichten-Anwendungsfälle verfügbar.
Komplexe Response-Parsing¶
Für APIs mit komplexen Response-Strukturen verwenden Sie den Custom Response Parser:
parser_config = client.llm_configs.create(
name="Multi-Model Ensemble",
llm_model_name="ensemble",
api_key="api-key",
llm_base_url="https://ensemble.ai/api",
inference_type="custom_api",
custom_api_config={
"headers": {"Authorization": "{{api_key}}"},
"body": {"input": "{{prompt}}"},
"response_mapping": {
"content_path": "outputs"
}
},
custom_response_parser="""
# Parse ensemble response with multiple model outputs
import json
response_data = json.loads(raw_response)
model_outputs = response_data.get('model_responses', [])
# Combine outputs with voting
combined = ' '.join([m['text'] for m in model_outputs if m['confidence'] > 0.7])
# Set the final parsed response
parsed_response = combined if combined else model_outputs[0]['text']
"""
)
Monitoring und Analyse¶
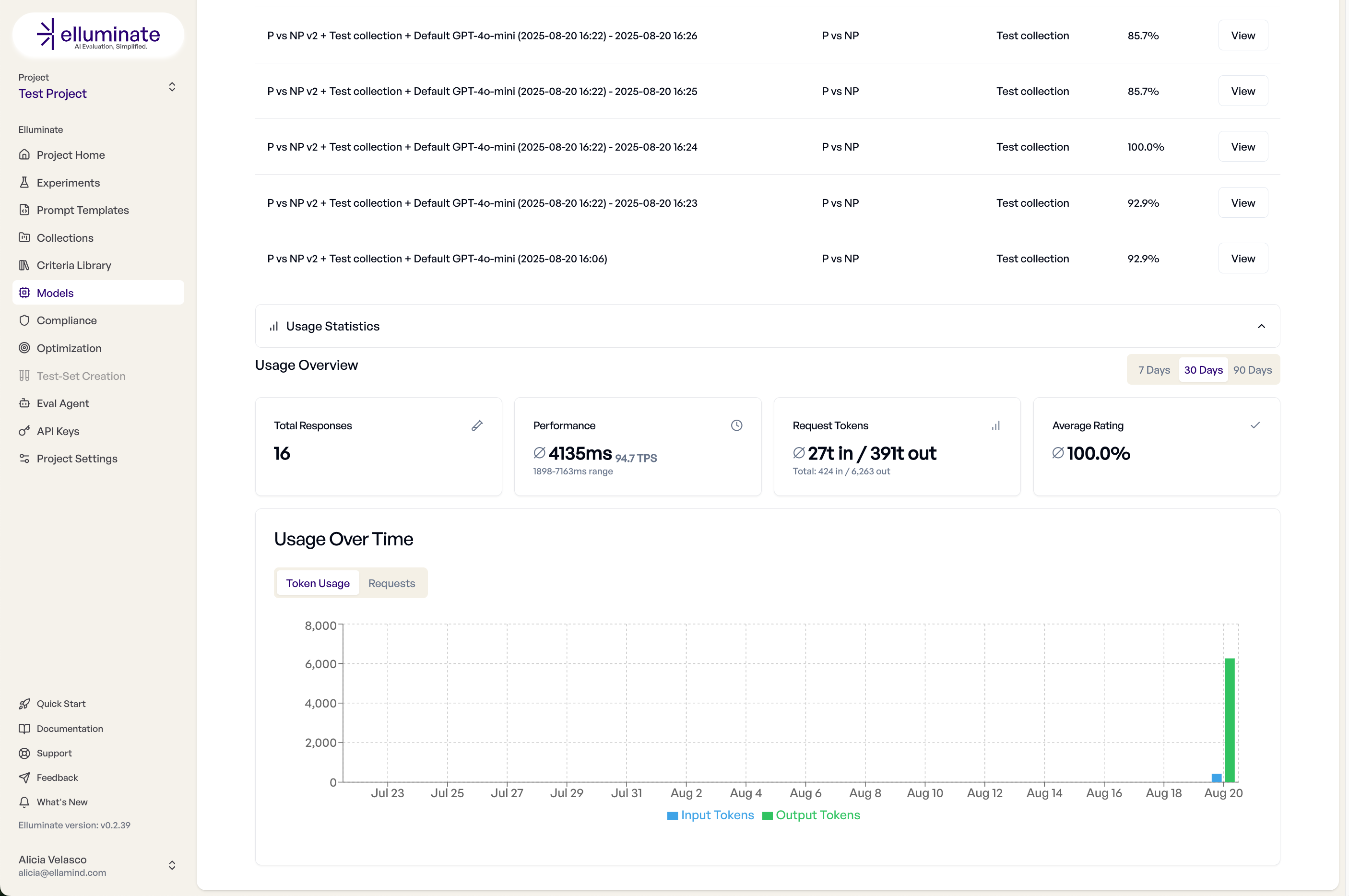
Usage-Dashboard¶
Um die Nutzung einer spezifischen Model Configuration zu verfolgen, können Sie die durchgeführten Experimente sowie einige Leistungsmetriken in den Configuration Details sehen.
Best Practices¶
Konfigurationsstrategie¶
- Development: Verwenden Sie günstigere, schnellere Modelle
- Staging: Testen Sie mit Produktionsmodellen
- Production: Optimieren Sie Parameter für Ihren Anwendungsfall
- Monitoring: Richten Sie Ihre eigenen Endpunkte für volle Kontrolle ein
Custom API Best Practices¶
- Standardisieren Sie das Response-Format: Verwenden Sie konsistente JSON-Strukturen
- Fügen Sie Metadaten hinzu: Geben Sie Modellversion, Latenz und Konfidenz zurück
- Fehlerbehandlung: Liefern Sie klare Fehlermeldungen
- Rate Limiting: Implementieren Sie angemessenes Throttling
- Monitoring: Protokollieren Sie alle Anfragen für Analysen
Troubleshooting¶
Häufige Probleme¶
Verbindung fehlgeschlagen
- Überprüfen Sie, ob der API Key gültig ist
- Überprüfen Sie das Base URL Format
- Stellen Sie sicher, dass die Netzwerkverbindung funktioniert
- Prüfen Sie die Firewall-Regeln
Langsame Antworten
- Reduzieren Sie max_tokens
- Senken Sie die temperature
- Überprüfen Sie die API Rate Limits
- Überdenken Sie die Modellgröße
Inkonsistente Ergebnisse
- Senken Sie die temperature für Determinismus
- Setzen Sie den seed Parameter, falls verfügbar
- Verwenden Sie konsistente System Prompts
- Überprüfen Sie die Modellversion