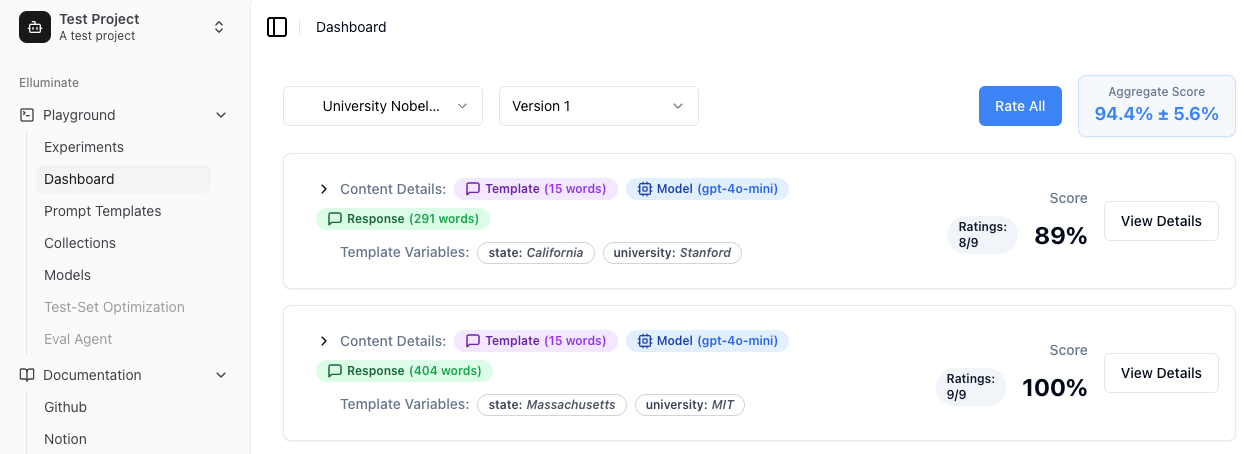
Ratings¶
Ein Rating (Bewertung) ist eine Methode zur Bewertung der Qualität einer Antwort auf einen Prompt. Ratings werden erstellt, indem die Antwort mit einem Kriterium verglichen wird. Das Dashboard zeigt bewertete Antworten mit detaillierten Metriken an und ermöglicht eine interaktive Analyse der Evaluierungsergebnisse. Ein typischer Rating-Eintrag sieht wie folgt aus:
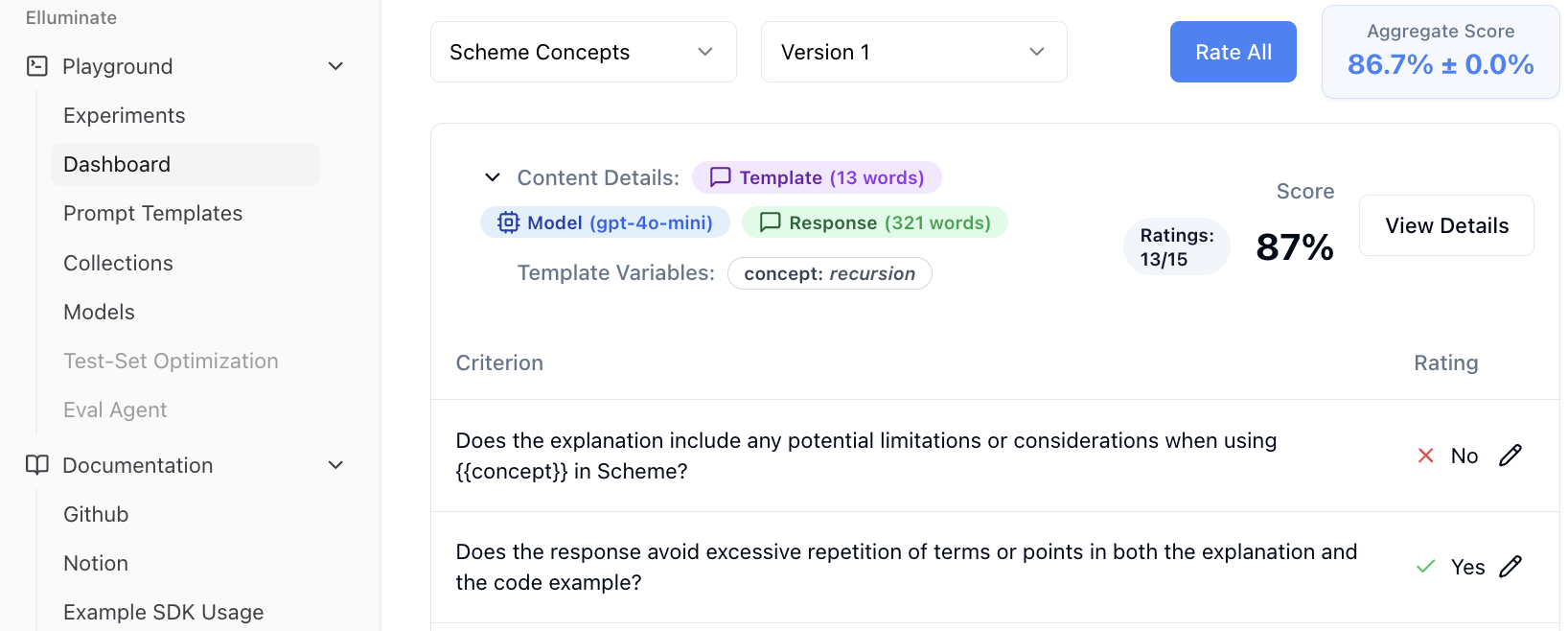
Hier können Sie sehen:
- Gesamtrating, zusammengefasst aus einzelnen Kriterienbewertungen
- Einzelratings für jedes Evaluierungskriterium
- LLM-Konfigurationsdetails, die zur Generierung der Antwort verwendet wurden
- Wortanzahl-Statistiken sowohl für das Template als auch für die generierte Antwort
Falls das Rating einzelner Kriterien nicht korrekt sein sollte, kann der Benutzer hier manuelle Verbesserungen vornehmen.
Rating mit generierten Kriterien und Antworten¶
Im Quick Start zeigen wir Ihnen, wie Sie ein einfaches Rating mehrerer Kriterien für eine Antwort durchführen können. In diesem Beispiel werden sowohl die Kriterien als auch die Antworten automatisch von Elluminate generiert.
Nützlich für:
- Schnelle Evaluierung: Bewerten Sie Antworten ohne manuelle Kriteriendefinition
- Qualitätsgenerierung: Generieren Sie hochwertige dynamische Kriterien basierend auf dem Prompt-Kontext
- Framework-Entwicklung: Erkunden oder prototypisieren Sie Evaluierungsframeworks
- KI-gestützte Bewertung: Nutzen Sie KI-generierte Kriterien für umfassende Ratings
-
Initialisiert den Elluminate-Client mit Ihren konfigurierten Umgebungsvariablen aus der Einrichtungsphase.
-
Erstellt ein Prompt-Template unter Verwendung der Mustache-Syntax und Template-Variablen (wie
conceptin diesem Beispiel). Wenn das Template bereits existiert, wird es einfach zurückgegeben. -
Generiert automatisch Evaluierungskriterien für Ihr Prompt-Template or holt die bereits existierenden Kriterien.
-
Erstellt eine Template-Variablen-Collection. Dies wird verwendet, um die Template-Variablen für ein Prompt-Template zu sammeln.
-
Fügt eine Template-Variable zur Collection hinzu. Dies wird verwendet, um die Template-Variable auszufüllen (ersetzt
conceptdurchrecursion). -
Erstellt eine Antwort durch Verwendung Ihres Prompt-Templates und Ausfüllen der Template-Variable.
-
Evaluiert die Antwort anhand der generierten Kriterien und gibt detaillierte Bewertungen für jedes Kriterium zurück.
Die generierten Kriterien werden dem Prompt Template zugeordnet und können einzeln in den Template Details eingesehen werden. Hier können Sie auch Einträge ändern oder löschen oder einen komplett neuen Generierungsprozess starten.
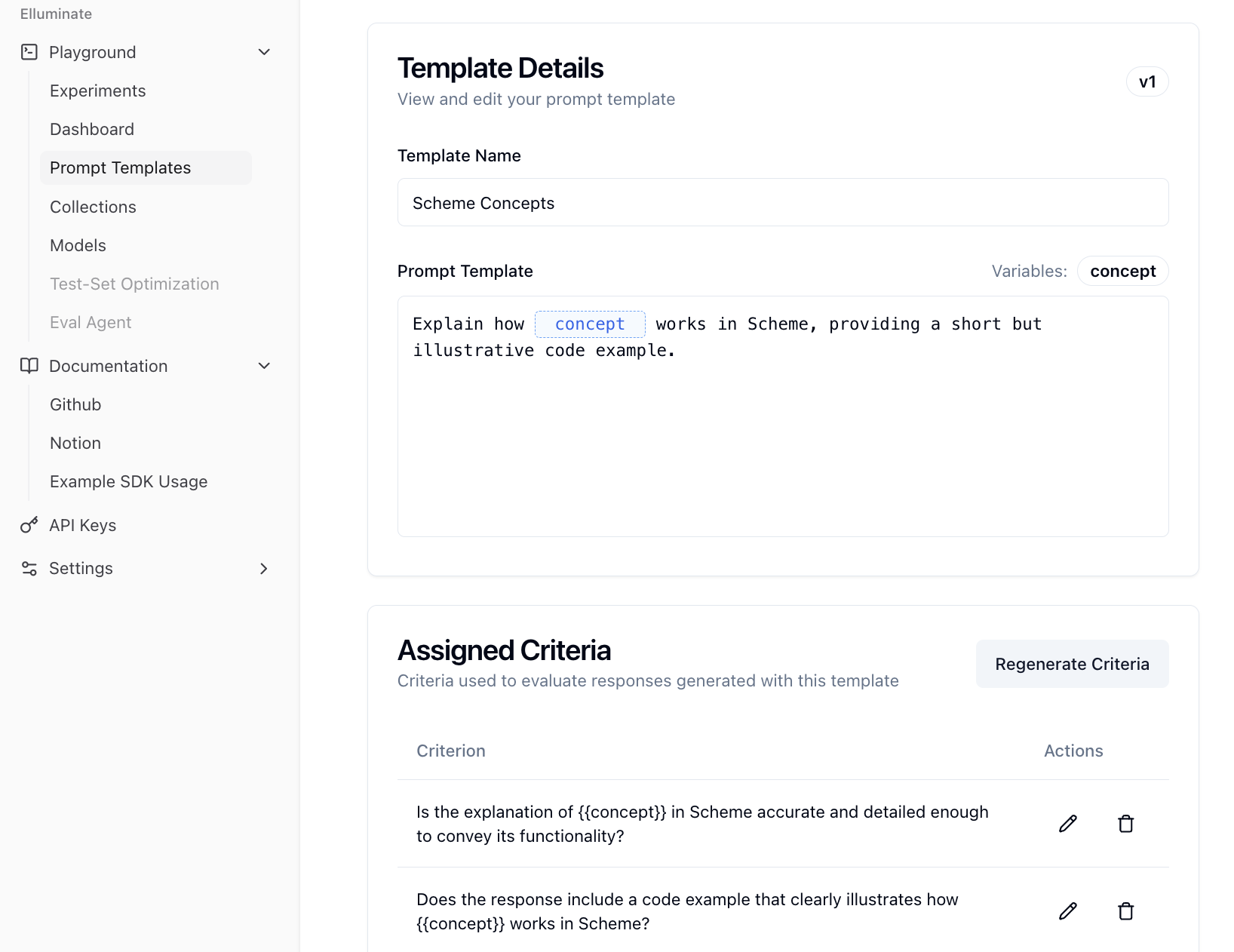
Die generierte Antwort kann durch Klicken auf View Details in der Dashboard-Ansicht angezeigt werden. Dies öffnet die Prompt Response Detail View, die die entsprechende Antwort und den zugehörigen Prompt anzeigt.
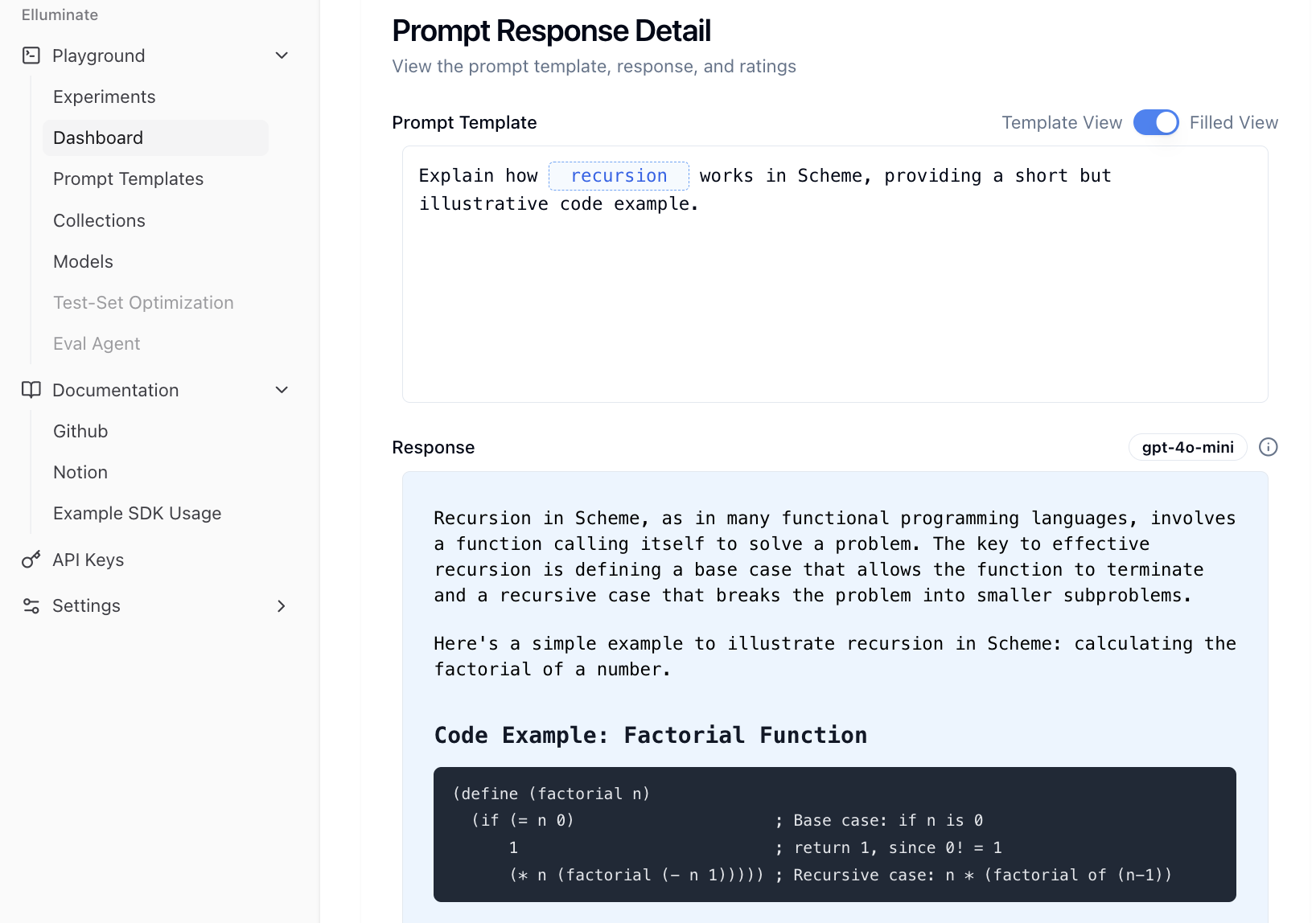
Rating benutzerdefinierter Kriterien und Antworten¶
Für mehr Kontrolle über den Evaluierungsprozess können Sie Kriterien und Antworten manuell festlegen. Dies ist besonders nützlich, wenn Sie:
- Benutzerdefinierte Qualitätsstandards: Definieren und durchsetzen spezifischer Qualitätskriterien für Ihren Anwendungsfall
- Externe Antwortbewertung: Bewerten von Antworten aus beliebigen Quellen, nicht beschränkt auf durch Elluminate generierte
- Standardisierte Tests: Anwenden einheitlicher Bewertungskriterien zur Wahrung der Konsistenz über Testsuiten hinweg
-
Hinzufügen benutzerdefinierter Kriterien zu einem gegebenen Prompt Template. Die Verwendung von
delete_existing=Truestellt sicher, dass alle existierenden Kriterien vor dem Hinzufügen der neuen entfernt werden. Dies gibt Ihnen volle Kontrolle darüber, welche Aspekte der Antwort bewertet werden. -
Erstellen Sie eine Collection, in die wir eine einzelne Template Variable zur Inferenz und anschließenden Bewertung hinzufügen werden.
-
Manuelles Hinzufügen der Antwort mit entsprechenden Metadaten. Die Antwort wird verknüpft mit:
- Dem Prompt Template
- Template Variables (um zu wissen, welcher Prompt sie generiert hat)
- Dem Experiment (um Ratings an einem Ort zu aggregieren)
- LLM-Konfigurationsmetadaten (um zu verfolgen, welches Modell und welche Einstellungen verwendet wurden)
Rating einer Reihe von Prompts¶
Wenn Sie mehrere Variationen von Template Variables testen möchten, können Sie eine TemplateVariablesCollection (oder einfach Collection) verwenden, um diese zu organisieren und gemeinsam zu evaluieren. Dies ist essentiell für die systematische Bewertung der Prompt-Leistung über verschiedene Eingaben hinweg.
Dieser Ansatz ist besonders leistungsfähig, wenn Sie:
- Input-Testing: Evaluieren, wie gut Ihr Prompt mit verschiedenen Testfällen und Grenzfällen funktioniert
- Leistungsanalyse: Trends und Muster erkennen, wie Ihr Prompt auf verschiedene Eingaben reagiert
- Iterative Optimierung: Erkenntnisse aus Tests nutzen, um Ihr Prompt Template zu verfeinern und zu verbessern
- Definieren Sie Ihre Testfälle als Template Variables
- Erstellen Sie eine Collection zur Speicherung Ihrer Testfälle
- Fügen Sie jeden Variablensatz zur Collection hinzu
- Das Prompt Template muss mit Ihren Variablen kompatibel sein
- Generieren Sie Antworten für alle Testfälle in der Collection
Die Collections-Ansicht bietet einen organisierten Überblick über Ihre Template Variables Sets. Jede Collection wird durch ihren Namen identifiziert und enthält mehrere Einträge, wobei Zeitstempel anzeigen, wann sie hinzugefügt wurden.
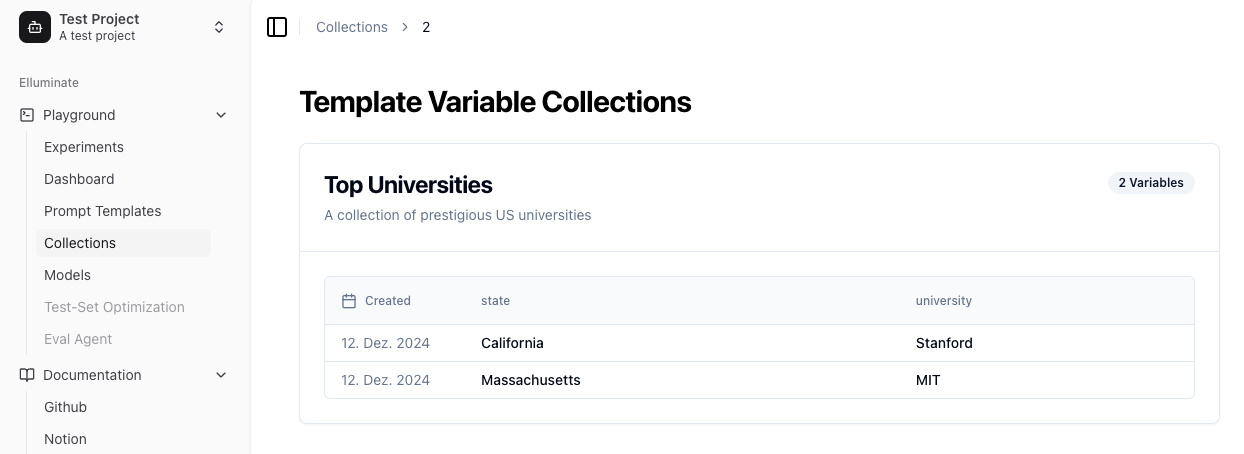
Wenn Sie zur Dashboard-Ansicht gehen, können Sie das Prompt Template auswählen und die Bewertungen für jede Antwort zu allen Prompts sehen, die aus der Collection generiert wurden. Hier können Sie einfach überprüfen, wie die Antworten entsprechend einem Eintrag in der Collection abschneiden.