Conversations¶
Evaluate multi-turn dialogues and conversation-dependent prompts with systematic context management
Conversations enable you to test prompts that require conversation history or multi-turn dialogue context. Whether you're building chatbots, customer support systems, or any LLM application that maintains context across interactions, the conversation feature lets you systematically evaluate how your prompts perform with different conversation histories.
What Are Conversations?¶
Conversations in elluminate are structured message histories that provide context for prompt evaluation. Instead of testing prompts in isolation, conversations let you:
- Test multi-turn dialogues - Evaluate how your LLM and prompt handle ongoing conversations
- Provide conversation history - Give your LLM the context of previous messages
- Evaluate context awareness - Verify your prompt maintains coherence across turns
- Test with realistic scenarios - Use actual conversation transcripts from your system
A conversation is stored as a special payload in your collection that contains:
- Messages - The conversation history (system, user, assistant, tool messages)
- Tools (optional) - Tool definitions available during the conversation
- Tool choice (optional) - How the model should use tools
- Response format (optional) - Structured output requirements
- Metadata (optional) - Additional configuration like merge modes
How Conversations Work¶
The Conversation Column¶
Conversations are stored in a special Conversation column type in your collections. This column:
- Contains structured conversation payloads (not plain text)
- Can only exist once per collection
- Cannot coexist with Raw Input columns
- Cannot be renamed after creation
The Raw Input Column¶
Raw Inputs are in direct contrast to conversations a single prompt that is directly sent to the LLM. It does not allow for placeholders, and can not be used in combination with conversations.
Raw Inputs simplify the use-case in which you want to test specific variations of a prompt directly against an LLM.
On a technical level, raw inputs are a simplifed conversation with just one single user message.
Message Flow¶
When you run an experiment with conversations, elluminate:
- Optionally adds your template - If provided, we fill your prompt template placeholders with values from the collection
- Appends conversation messages - Adds the conversation history after the prompt template
- Sends to LLM - The model sees the full constructed message history
- Evaluates the response - We rate based on criteria with full conversation context
Example message order:
1. System message from template
2. User message from template (with placeholders filled)
3. User message from conversation payload
4. Assistant message from conversation payload
5. User message from conversation payload
-> LLM generates response here
Setting Up Conversations¶
Step 1: Create a Collection with a Conversation Column¶
Via the UI¶
- Navigate to your project's Collections page
- Click "New Collection" or open an existing collection
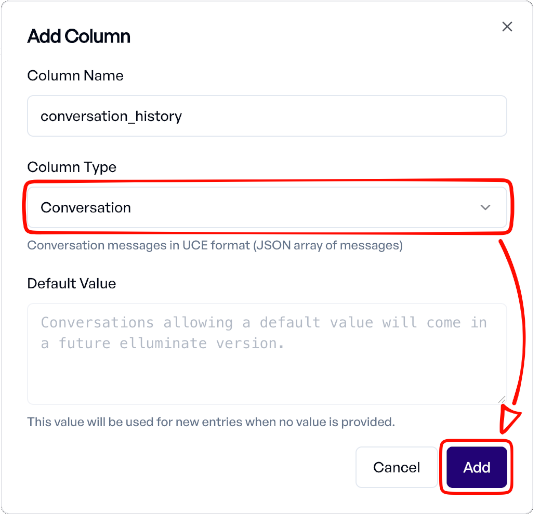
- Click the "Add Column" button (+ icon) in the table header
- Configure the column:
- Name: Choose a descriptive name (e.g.,
conversation,chat_history) - Type: Select "Conversation"
- Default Value: Leave empty (conversation columns don't use default values at the moment)
Conversation Column Restrictions:
- Only one conversation column per collection
- Cannot coexist with a Raw Input column
- Column name cannot be changed after creation
- Must contain valid conversation payloads
Step 2: Add Conversation Data¶
Conversation Payload Format¶
Conversations use the Messages schema:
"messages": [
{"role": "user", "content": "Hello!"},
{"role": "assistant", "content": "Hi! How can I help?"},
{"role": "user", "content": "I need help with my account."}
]
Or Unified Conversation Envelope (UCE) schema (everything except messages is optional):
{
"schema_version": "elluminate.uce/1",
"input": {
"messages": [
{"role": "user", "content": "Hello!"},
{"role": "assistant", "content": "Hi! How can I help?"},
{"role": "user", "content": "I need help with my account."}
],
"tools": [...],
"tool_choice": "auto",
"response_format": {...},
"metadata": {...}
}
}
Message Roles¶
Messages support these roles:
system- System instructions or contextuser- User messagesassistant- Assistant responsestool- Tool execution results
Adding Conversation Data via UI¶
- Open your collection
- Click "Add Variables"
- For the conversation column, paste a valid JSON payload
- Optionally, fill in other columns (e.g., scenario description)
- Click the checkmark on the right to save

Bulk Import via File Upload¶
Prepare a JSONL file where each conversation value follows the UCE format:
{"conversation": {"schema_version": "elluminate.uce/1", "input": {"messages": [...]}}, "scenario": "password_reset", "category": "account"}
{"conversation": {"schema_version": "elluminate.uce/1", "input": {"messages": [...]}}, "scenario": "billing_inquiry", "category": "support"}
Then upload via:
- Go to the collections page and open the collection
- Click "Upload variables" and select the JSONL file
- Confirm the upload
Using Conversations in Experiments¶
Conversations work seamlessly with and without prompt templates. The template provides initial context, and the conversation provides dialogue history.

Advanced Features¶
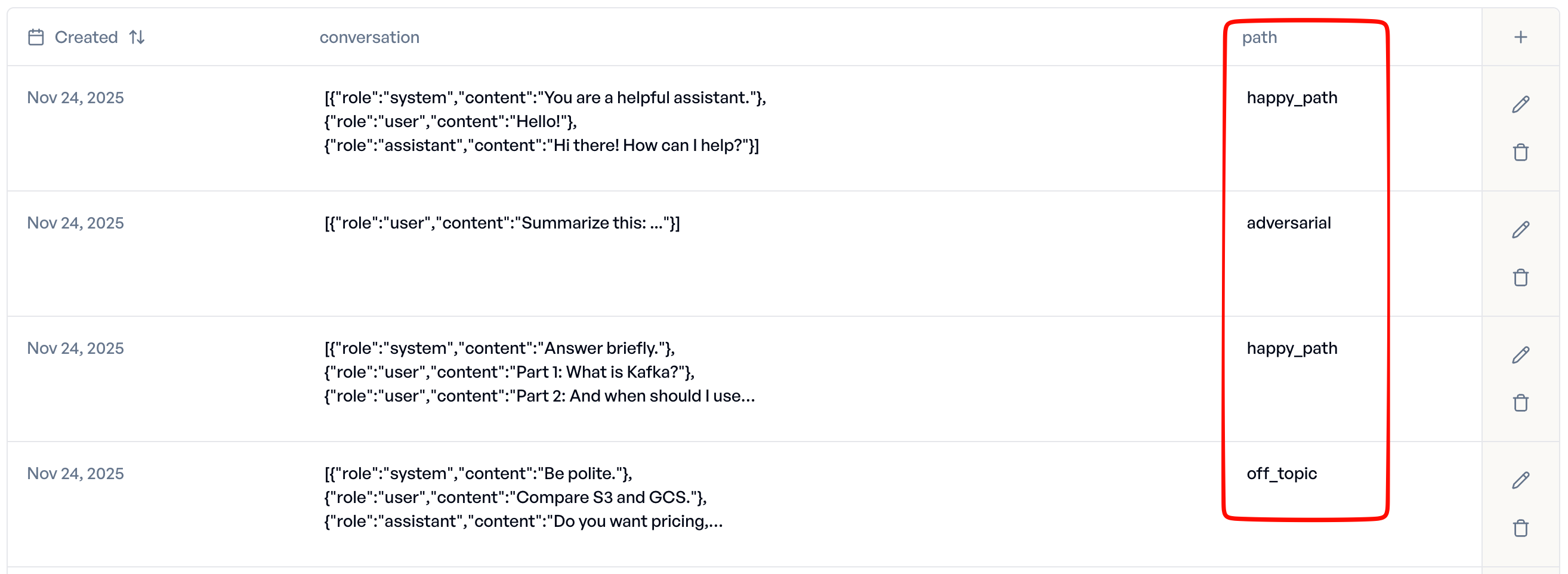
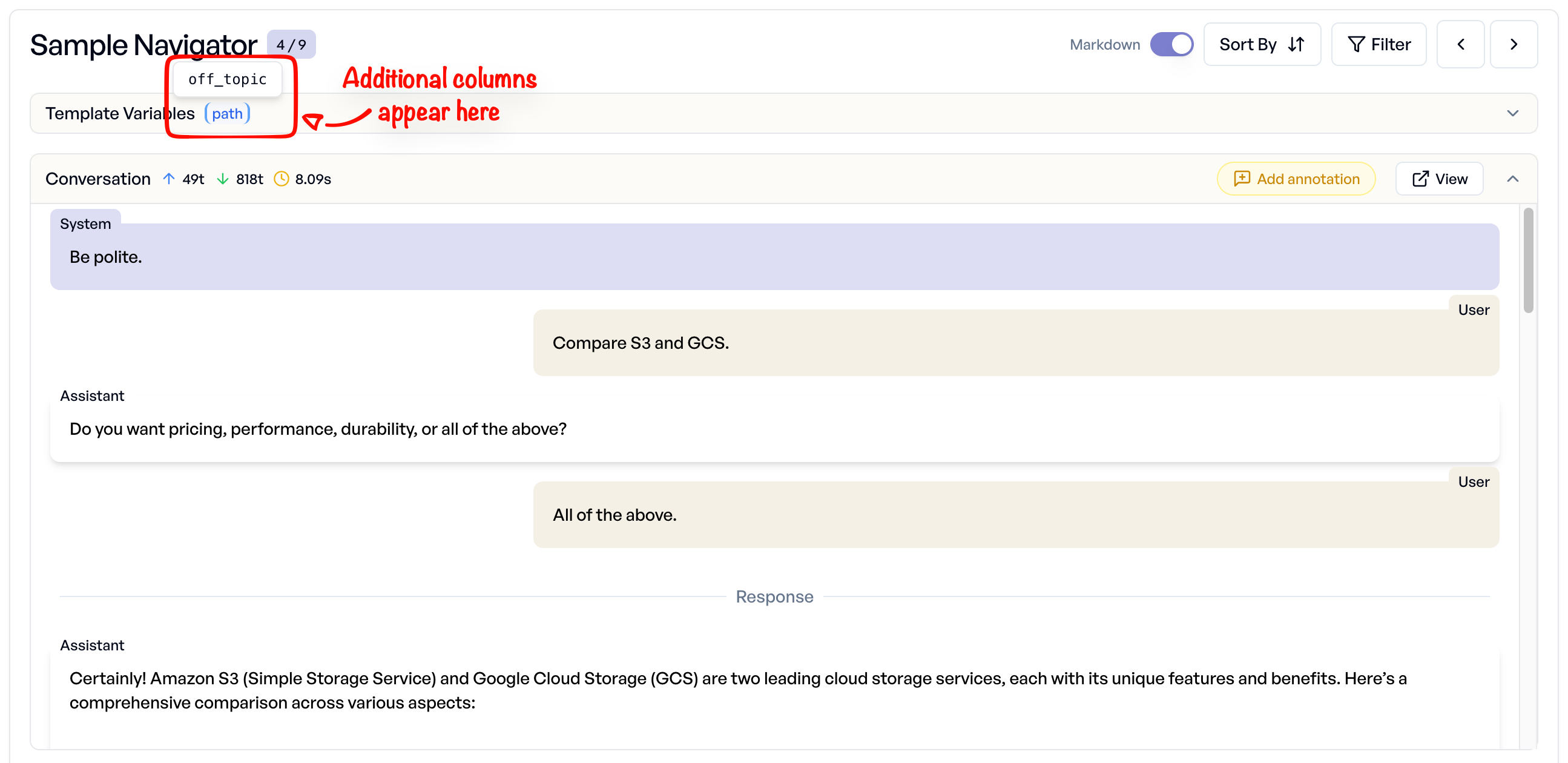
Combining with Other Columns¶
You can mix conversation columns with regular text columns to add metadata:
Tool Calling in Conversations¶
Include tool definitions in your conversation payload:
{
"schema_version": "elluminate.uce/1",
"input": {
"messages": [
{"role": "user", "content": "Check my account balance."}
],
"tools": [
{
"type": "function",
"function": {
"name": "get_account_balance",
"description": "Retrieves the current account balance",
"parameters": {
"type": "object",
"properties": {
"account_id": {"type": "string"}
},
"required": ["account_id"]
}
}
}
],
"tool_choice": "auto"
}
}
Merging Tools¶
When both your template and conversation define tools, they merge by default. Control this with merge modes:
{
"schema_version": "elluminate.uce/1",
"input": {
"messages": [...],
"tools": [
// Only these tools will be available
],
"metadata": {
"merge_mode": {
"tools": "replace" // Or "merge" (default)
}
}
}
}
Response Format Control¶
Specify output format per conversation with a JSON schema:
{
"schema_version": "elluminate.uce/1",
"input": {
"messages": [...],
"response_format": {
"json_schema": {
"name": "customer_summary",
"schema": {
"type": "object",
"properties": {
"issue": {
"type": "string"
},
"priority": {
"type": "string",
"enum": ["low", "medium"]
}
},
"required": ["issue", "priority"]
}
}
}
}
}
Practical SDK Examples¶
Example 1: Customer Support Chatbot¶
Create a collection with conversation column:
from elluminate import Client
from elluminate.schemas import CollectionColumn, ColumnTypeEnum, RatingMode
client = Client()
# Create collection with conversation column
collection, _ = client.get_or_create_collection(
name="Customer Support Scenarios",
defaults={
"columns": [
CollectionColumn(
name="conversation",
column_type=ColumnTypeEnum.CONVERSATION,
column_position=0,
),
CollectionColumn(
name="scenario_type",
column_type=ColumnTypeEnum.CATEGORY,
column_position=1,
),
]
},
)
Add conversation data:
# Add a password reset conversation using UCE format
password_reset_conversation = {
"schema_version": "elluminate.uce/1",
"input": {
"messages": [
{"role": "user", "content": "I can't log into my account."},
{
"role": "assistant",
"content": "I can help you with that. Can you tell me your email address?",
},
{"role": "user", "content": "It's [email protected]"},
{
"role": "assistant",
"content": "Thank you. I've found your account. Would you like me to send a password reset link?",
},
{"role": "user", "content": "Yes please."},
]
},
}
collection.add_many(
variables=[
{
"conversation": password_reset_conversation,
"scenario_type": "password_reset",
}
],
)
Set up evaluation criteria:
# Create evaluation criteria for conversation quality
criteria = [
"Does the assistant maintain a professional and helpful tone throughout?",
"Does the assistant successfully guide the user to resolve their issue?",
"Does the assistant ask appropriate follow-up questions?",
]
criterion_set, _ = client.get_or_create_criterion_set(
name="Customer Support Quality",
defaults={"criteria": criteria},
)
Run the experiment:
# Create and run the experiment
experiment = client.run_experiment(
name="Support Conversation Quality",
prompt_template=None, # No prompt template needed with conversations
collection=collection,
criterion_set=criterion_set,
description="Evaluating customer support conversation quality",
rating_mode=RatingMode.FAST,
llm_config=llm_config,
)
Example 2: Multi-Turn Technical Support¶
# Technical troubleshooting conversation with more turns
tech_support_conversation = {
"schema_version": "elluminate.uce/1",
"input": {
"messages": [
{"role": "user", "content": "My app keeps crashing."},
{"role": "assistant", "content": "I'm sorry to hear that. What device are you using?"},
{"role": "user", "content": "iPhone 14 with iOS 17."},
{
"role": "assistant",
"content": "Thank you. Have you tried updating the app to the latest version?",
},
{"role": "user", "content": "Yes, it's already updated."},
{
"role": "assistant",
"content": "Let's try clearing the app cache. Go to Settings > Apps > [App Name] > Clear Cache.",
},
{"role": "user", "content": "Okay, I did that. Now what?"},
]
},
}
collection.add_many(
variables=[
{
"conversation": tech_support_conversation,
"scenario_type": "technical_troubleshooting",
}
],
)
Example 3: Tool Calling in Conversations¶
# Conversation with tool calling
tool_calling_conversation = {
"schema_version": "elluminate.uce/1",
"input": {
"messages": [{"role": "user", "content": "Check my account balance."}],
"tools": [
{
"type": "function",
"function": {
"name": "get_account_balance",
"description": "Retrieves the current account balance",
"parameters": {
"type": "object",
"properties": {"account_id": {"type": "string"}},
"required": ["account_id"],
"additionalProperties": False,
},
},
}
],
"tool_choice": "auto",
},
}
collection.add_many(
variables=[
{
"conversation": tool_calling_conversation,
"scenario_type": "account_inquiry",
}
],
)
Best Practices¶
Structuring Conversation Data¶
Keep conversations focused
- Each conversation should test a specific scenario or use case
- Limit conversation length to relevant context (typically 3-10 messages)
- Remove irrelevant small talk or greetings unless testing those specifically
Use realistic conversation patterns
- Include typical user messages (typos, incomplete sentences, varied phrasing)
- Add assistant responses that reflect your system's actual behavior
- Include edge cases (unclear requests, off-topic questions)
Balance your test scenarios
- Happy paths (60-70%) - Normal conversations that should work well
- Edge cases (20-30%) - Unusual but valid conversation flows
- Adversarial cases (10-20%) - Attempts to confuse or break the system
Evaluation Strategy¶
Design conversation-aware criteria
Good criteria reference the conversation history:
- ✅ "Does the assistant maintain consistency with information provided earlier in the conversation?"
- ✅ "Does the response appropriately address the user's follow-up question?"
- ❌ "Is the response helpful?" (too generic)
Test incremental conversation building
Instead of one long conversation, test progression:
- Conversation 1: Initial request
- Conversation 2: Initial request + one follow-up
- Conversation 3: Initial request + two follow-ups
This helps isolate where context awareness breaks down.
FAQ¶
Can I edit the conversation payload after adding it?¶
Yes, click the edit icon on the variables table row. Be careful to maintain valid JSON structure.
What happens if my conversation payload is invalid?¶
elluminate validates the payload when you save. You'll see an error message indicating what's wrong (e.g., "Missing required field 'messages'", "Invalid tool definition").
Can I use conversations with batch processing?¶
Yes! Conversations work with all experiment features including batch operations and async SDK methods.
How do conversations differ from Raw Input columns?¶
- Conversations: Structured message histories with optional tools/metadata. Can combine with templates.
- Raw Input: Single user message, cannot combine with templates. For simple, template-free testing.
Can I have multiple conversation columns?¶
No, only one conversation column per collection. This ensures clarity about which payload provides the conversation context.
Do conversation messages count toward token limits?¶
Yes, all messages (template + conversation) are sent to the LLM and count toward the model's context window.
Can I reference conversation data in criteria?¶
The rating model sees the full conversation when evaluating, so your criteria can reference "earlier in the conversation" or "the conversation history."