Criterion Sets¶
Organize evaluation criteria into reusable sets that enable consistent assessment
Criterion sets are collections of evaluation criteria that define how AI responses should be assessed. They enable systematic evaluation by grouping related criteria together, so they can be used easily in your experiments.
What are Criterion Sets?¶
A criterion set contains one or more criteria - binary evaluation questions that rate AI responses as "pass" or "fail." Each criterion asks a specific yes/no question about response quality, such as "Does the response answer the question accurately?" or "Is the response free from harmful content?".
Criterion sets provide consistency by applying the same evaluation standards across your experiments, enable reusability through shared criteria, and improve efficiency by reducing duplicate work when evaluating similar prompt variations.
Key Concepts¶
Criteria: Individual evaluation questions that assess specific aspects of response quality. Each criterion must be answerable with yes/no and should target one particular aspect of response quality.
Template Linking: Criterion sets can be linked to prompt templates. This association determines which criterion set will be selected by default for experiments with this prompt template. An alternative approach is to select the Criterion Set at the experiment creation time.
Collection Compatibility: Criterion sets must be compatible with collections to be used in experiments. Compatibility means that criteria placeholders (e.g., {{user_question}}) match the collection's column names exactly. When creating experiments, only compatible criterion sets are available for selection. When no placeholders are used in the Criteria, compatibility will be guaranteed to any collection.
Version Control: Automatic versioning tracks changes to criteria for reproducibility, ensuring experiments remain consistent even when criteria are updated.
Getting Started¶
Creating Your First Criterion Set¶
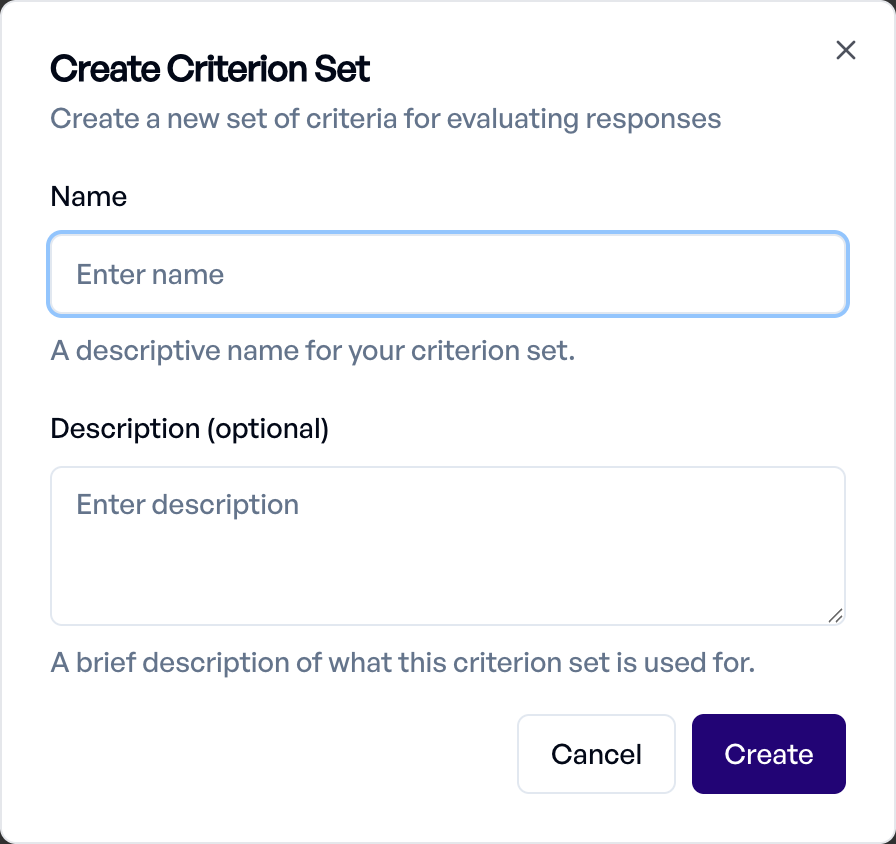
Navigate to Criteria Library in your project sidebar to manage all criterion sets. Click "New Criterion Set" to create your first set.
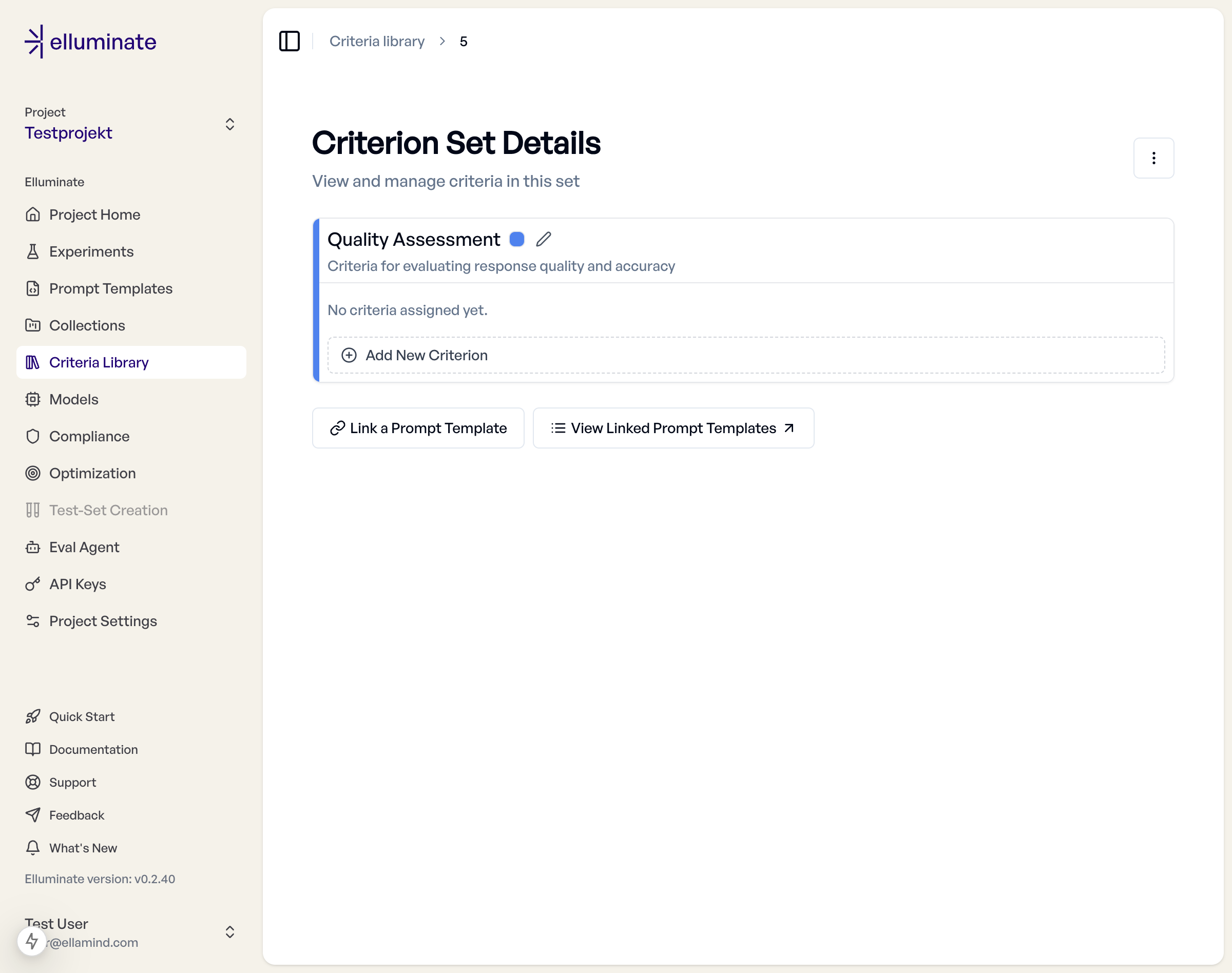
Required Information:
- Name: Descriptive identifier for the criterion set (e.g., "Content Safety", "Technical Accuracy")
- Description: Brief explanation of the set's purpose and scope
Adding Criteria¶
Once you've created a criterion set, click on it to add individual criteria. Each criterion should:
- Start with "Does" or "Is" for binary evaluation
- Focus on observable response characteristics
- Use clear, unambiguous language
- Target one specific aspect of response quality
Example Criteria:
- "Does the response provide accurate information?"
- "Is the response free from harmful content?"
- "Does the response follow the requested format?"
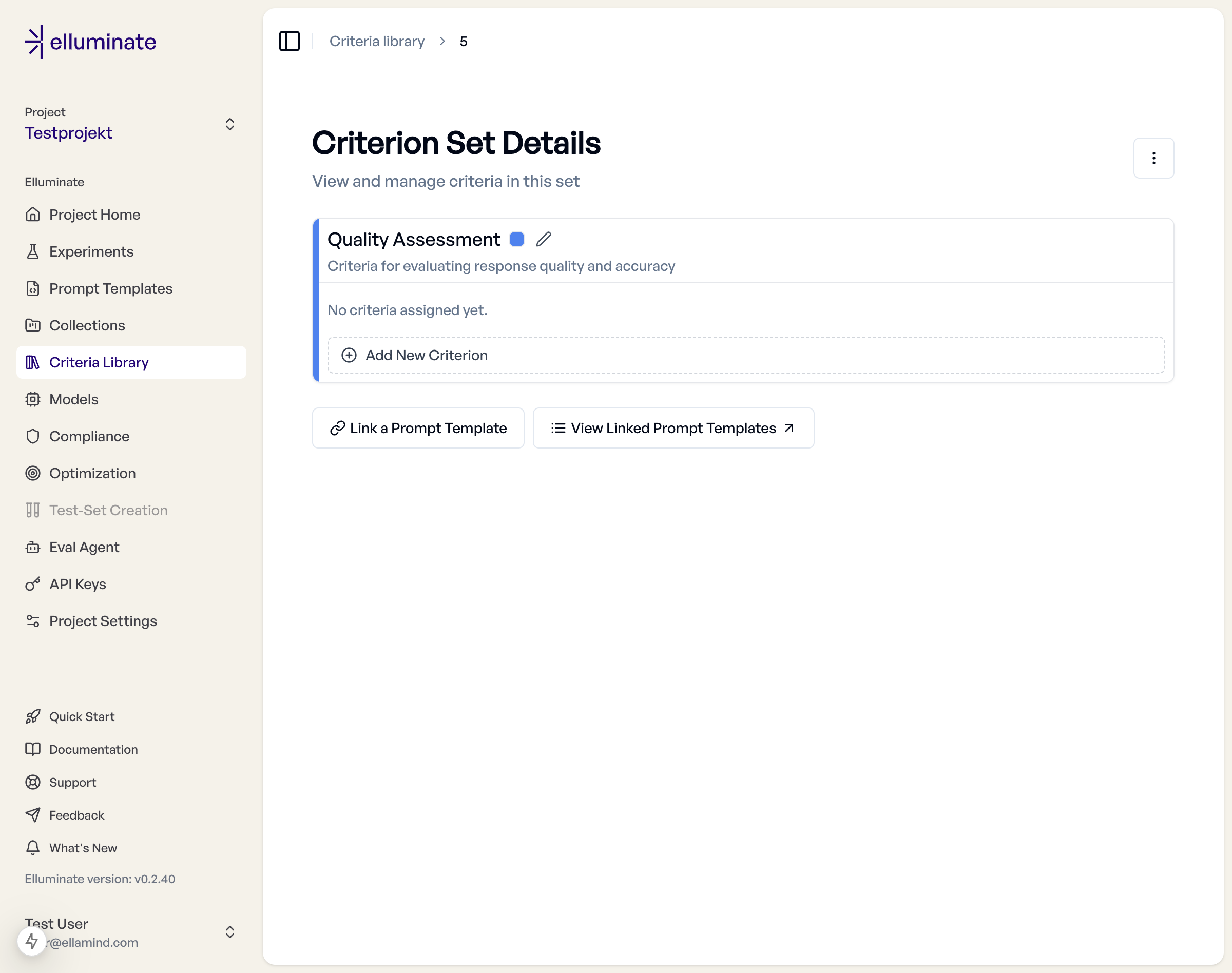
Linking to Templates¶
Criterion sets can be linked to prompt templates. You can link sets when creating templates or use the "Link a Prompt Template" feature to connect existing sets.
When you create experiments, the criterion set linked to your selected prompt template will be selected by default, but it is possible to replace it with another compatible one. The evaluation system generates responses, applies criteria to evaluate each response, and produces pass/fail ratings for each criterion.
Advanced Features¶
Template-Set Associations¶
Criterion sets can be linked to multiple templates, but this association is not fixed, and can be adjusted to your needs in each experiment. This flexibility allows you to:
- Apply universal criteria (safety, basic quality) across all templates
- Use specific criteria for particular use cases (customer service, technical documentation)
- Combine different evaluation focuses for comprehensive assessment
Managing Associations:
- View all templates linked to a specific criterion set
- Link a different criterion set to existing templates
- Unlink sets while preserving historical experiment data
Results and Analysis¶
Experiment results show performance by individual criterion, including pass rates for each criterion, response-level ratings showing which criteria passed/failed, and aggregate scores combining all criteria into overall template performance.
When comparing experiments over time, you can analyze trends in criterion performance to understand which aspects of your prompts are improving or need attention.
Best Practices¶
Set Organization Strategy¶
Organize criterion sets by purpose to maintain clarity and reusability. Common groupings include:
- Accuracy Sets - Content correctness, factual accuracy, completeness
- Safety Sets - Harmful content, bias detection, compliance requirements
- Quality Sets - Clarity, coherence, professional tone
- Functional Sets - Task completion, format adherence, instruction following
Criteria Design Guidelines¶
Design criteria to be comprehensive yet focused. Ensure your criteria cover all important evaluation dimensions while maintaining balanced expectations that are neither too lenient nor impossibly strict.
Focus on actionable feedback - results should indicate specific improvement areas rather than just pass/fail status. Use clear, unambiguous language that minimizes subjective interpretation.
Workflow Integration¶
Define criteria before creating prompt templates to ensure evaluation standards are established early. Create criterion sets for each major evaluation category and link the most commonly used to your prompt template.
Validate criteria through initial experiment runs and iterate based on evaluation results. For team collaboration, use consistent criterion sets across team members and maintain clear documentation of what each criterion tests.
SDK Integration¶
For programmatic criterion set management, use the elluminate SDK:
from elluminate import Client
client = Client() # Uses ELLUMINATE_API_KEY env var
# v1.0: get_or_create_prompt_template - messages is part of lookup
template, _ = client.get_or_create_prompt_template(
name="Product Review Template",
messages="Please review this product: {{product_name}}. {{product_description}}",
)
collection, _ = client.get_or_create_collection(
name="Reviews Collection",
defaults={
"variables": [
{
"product_name": "elluminate Socks",
"product_description": "elluminate Socks are the best socks in the world.",
}
]
},
)
# v1.0: get_or_create_criterion_set (name is lookup key)
criterion_set, _ = client.get_or_create_criterion_set(
name="Shipping-related Criteria",
defaults={"criteria": ["Is the review at least two sentences long?"]},
)
# v1.0: Rich model method - link criterion set to template
criterion_set.link_template(template)
experiment = client.run_experiment(
name="Experiment with Criterion Set",
prompt_template=template,
collection=collection,
criterion_set=criterion_set,
llm_config=llm_config,
)
For complete SDK documentation, see the API Reference.
Troubleshooting¶
Common Issues¶
Inconsistent Results: Verify that criteria are written as binary yes/no questions. Compound questions that test multiple aspects can lead to inconsistent evaluations. A positive answer to the question will lead to a "Pass" Rating, so consider if your case should include criteria written as negative questions.
Missing Evaluations: Confirm that your LLM responses are in a format compatible with your criteria. Some criteria may require specific response structures or content types.
Criterion Set Not Available for Experiment: If your criterion set doesn't appear when creating an experiment, check that the criteria placeholders match your collection's column names exactly. Only compatible criterion sets are shown in the experiment creation form.
Getting Help¶
When criterion sets don't behave as expected, check the experiment logs for specific error messages, validate that criteria are properly linked to templates, and review criterion wording for clarity and objectivity.
Understanding criterion sets enables systematic, reproducible evaluation of AI responses while maintaining consistency across your evaluation workflows.