Structured Outputs¶
Master the evaluation of programmatically formatted LLM responses essential for agentic applications
Structured outputs enable the developer to enforce that the LLM produces responses formatted in a programatically deterministic manner. Agentic programs make great use of this feature to enable interoperability code paths and LLM responses. This makes evaluating structured outputs an essential part for evaluating agents.
Basic Usage¶
An example showcasing using Pydantic models for structured output generation and evaluation:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 | |
- Define Schema: Create a Pydantic model with field descriptions and basic constraints to define the exact JSON structure you want the LLM to return
- Create Template: Use the
response_formatparameter when creating a prompt template to specify that responses should follow your Pydantic model structure - Add Criteria: Define evaluation criteria that reference specific schema fields - criteria may also be auto-generated as per usual
- Run Experiment: Create and run experiments normally - the structured output format will be enforced automatically for all response generations
- Access Responses: The structured outputs can be found in the assistant message's
contentkey as a JSON string
Schema Definition Methods¶
Pydantic Models¶
Pydantic models provide the most intuitive and recommended way to define structured output schemas. Simply set the response_format to the Pydantic class definition, and elluminate handles the rest.
OpenAI JSON Schema Format¶
In addition to Pydantic models, you may also set the response_format directly with an OpenAI JSON Schema definition:
schema = {
"type": "json_schema",
"json_schema": {
"name": "sentiment",
"schema": {
"type": "object",
"properties": {
"stars": {
"type": "integer",
"description": "Number of stars of the review",
"minimum": 1,
"maximum": 5
},
"sentiment": {
"type": "string",
"description": "The sentiment output, could be positive, negative, or neutral.",
"enum": [
"positive",
"negative",
"neutral"
]
},
"confidence": {
"type": "number",
"description": "Confidence score of the sentiment analysis between 0 and 1",
"minimum": 0,
"maximum": 1
}
},
"required": [
"stars",
"sentiment",
"confidence"
],
"additionalProperties": False
}
}
}
AI-Powered Schema Generation¶
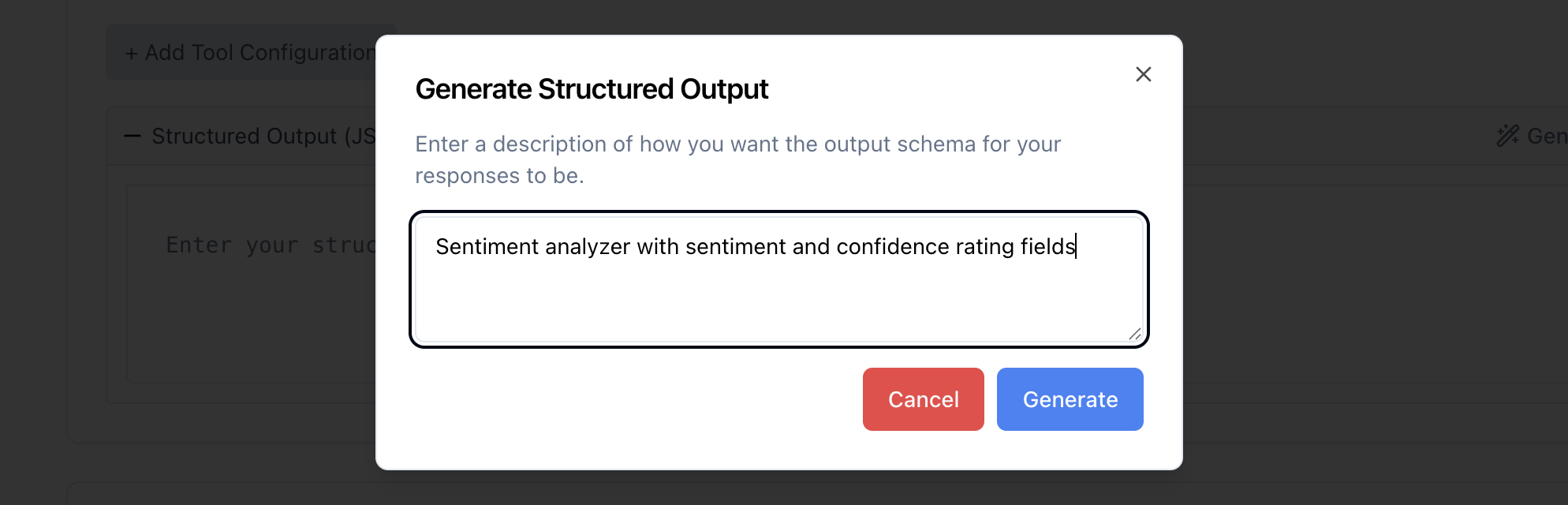
The frontend provides an AI-powered schema generator that creates JSON schemas from natural language descriptions. Simply describe what you want to extract, and elluminate will generate an appropriate schema.
Evaluating Structured Outputs¶
The rating model has access to all field descriptions from your structured output schema, providing valuable context about what each field should contain and how it should be interpreted. Subsequently to evaluate structured outputs, simply create criteria and run an experiment as per usual.
Using Field Names in Criteria
It may be beneficial to use field names from your schema in the criteria. This helps the rating model understand exactly which part of the JSON structure to focus on. For example, "Does the 'sentiment' field..." is more precise than "Is the sentiment correct?"