LLM Configs¶
Konfigurieren und verwalten Sie die Sprachmodelle, die Ihre Evaluierungen antreiben
Übersicht¶
elluminate bietet einige LLM Modelle, die standardmäßig konfiguriert sind, und ermöglicht es Ihnen, beliebige weitere Sprachmodelle mit Ihren Projekten zu verbinden — von beliebten Anbietern wie OpenAI bis hin zu Ihren eigenen benutzerdefinierten KI-Anwendungen. Diese Flexibilität ermöglicht es Ihnen, Prompts über verschiedene Modelle hinweg zu testen, Ihre bereitgestellten KI-Systeme zu überwachen und für Kosten und Leistung zu optimieren.
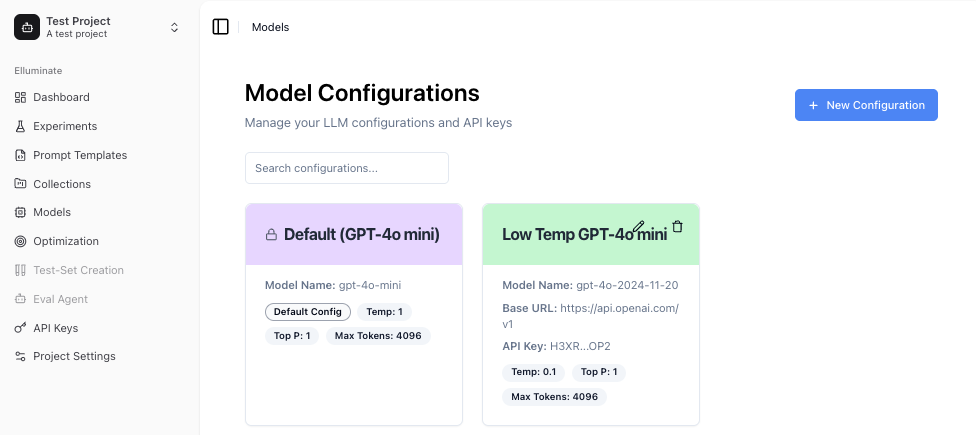
Konfiguration erstellen¶
Um eine neue LLM-Konfiguration zu erstellen, navigieren Sie zur Models-Seite in Ihrem Projekt und klicken Sie auf Create.
Grundeinstellungen¶
Geben Sie einen Namen und eine optionale Beschreibung ein, wählen Sie dann Ihren Provider (OpenAI, BCVP API oder Custom API). Je nach Provider füllen Sie den Modellnamen, die Base URL und den API Key aus.
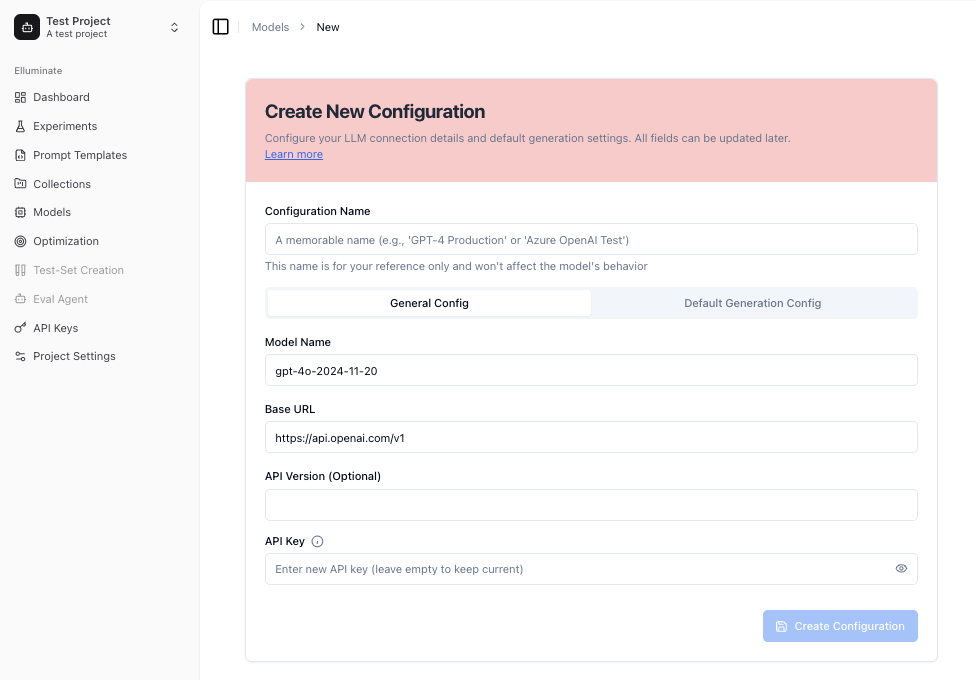
Die Verwendung einer anderen Base URL und eines anderen API Keys ermöglicht es Ihnen, Ihre Verbindung über ein benutzerdefiniertes Gateway oder einen Proxy zu leiten.
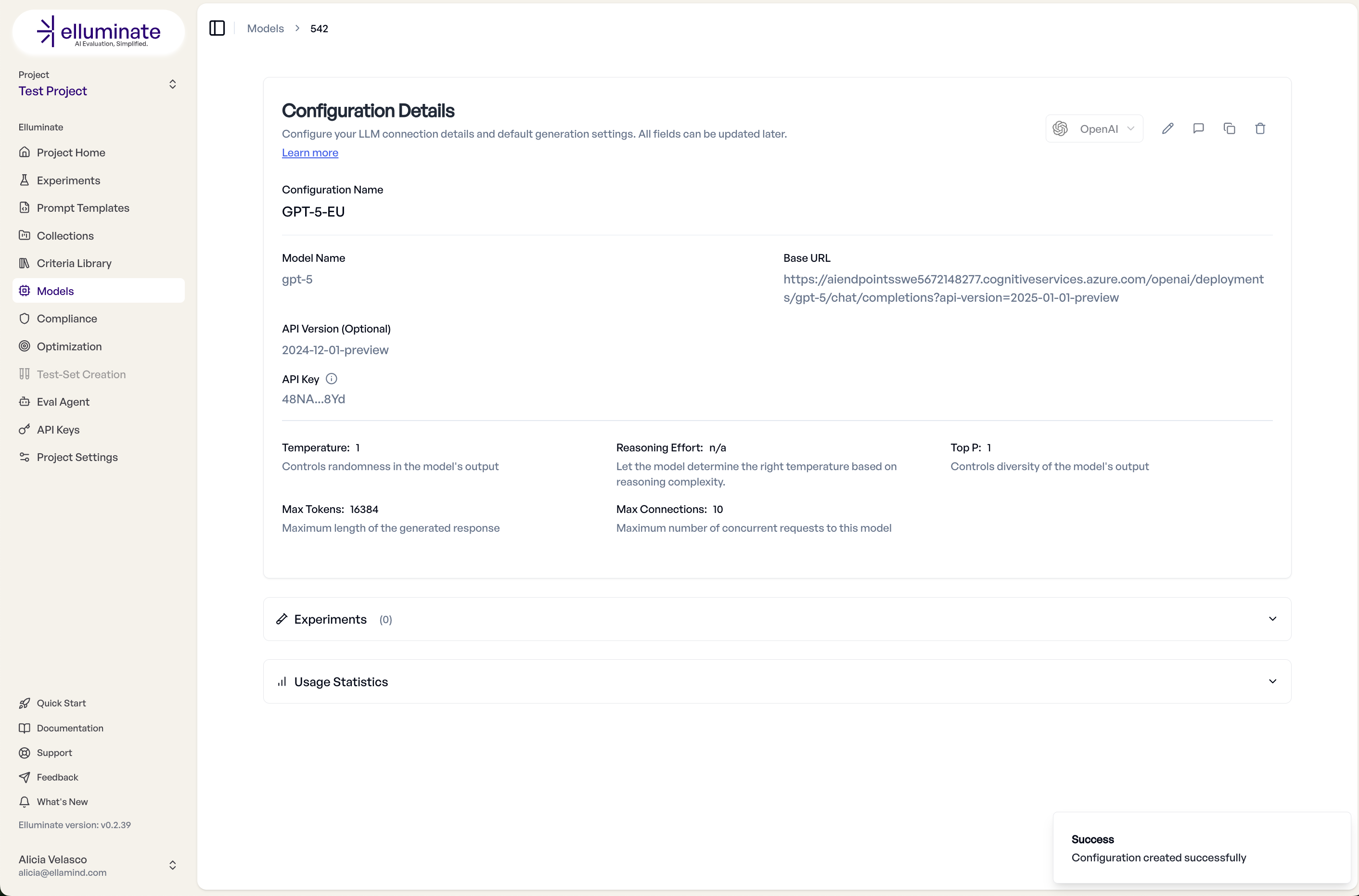
Generierungsparameter¶
Unter Advanced Settings können Sie die Antwortgenerierung des Modells feinabstimmen:
- Temperature (0–2): Steuert die Zufälligkeit. Niedrigere Werte erzeugen deterministischere Ausgaben.
- Top P (0–1): Nucleus-Sampling-Schwellenwert. Niedrigere Werte schränken den Token-Pool ein.
- Max Tokens: Maximale Antwortlänge.
- Max Connections: Anzahl paralleler Anfragen, die elluminate an dieses Modell senden kann.
- Reasoning Effort: Für neuere Reasoning-Modelle (o-Serie) steuert dies die Tiefe des Chain-of-Thought-Reasonings.
Für Standardkonfigurationen können Sie die Standardwerte des Anbieters verwenden, indem Sie das Kontrollkästchen anklicken.
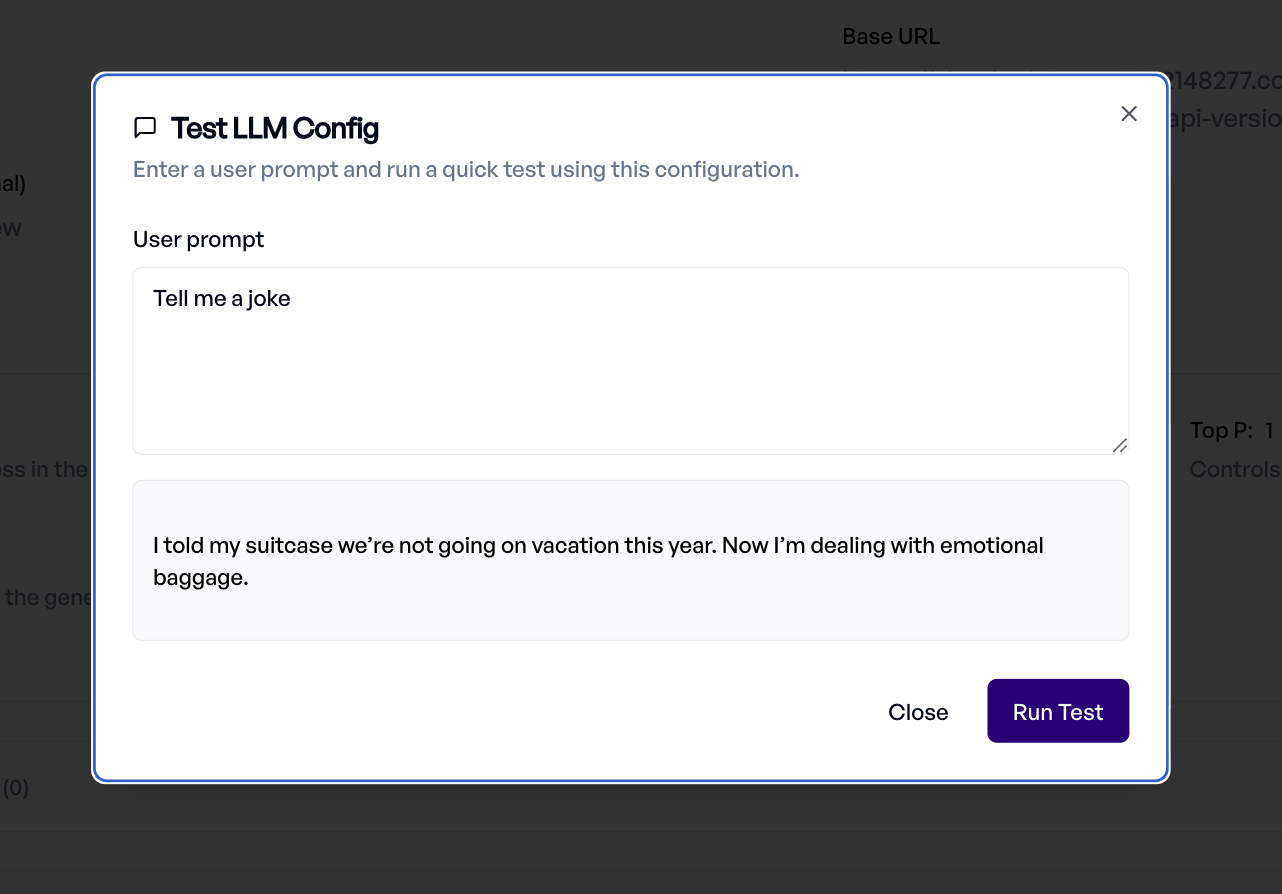
Konfiguration testen¶
Sobald konfiguriert, klicken Sie auf Test Configuration, um die Verbindung zu überprüfen. Geben Sie einen Test-Prompt ein und prüfen Sie die Antwort direkt im Dialog.
Benutzerdefinierte API-Endpunkte¶
Mit Custom API Endpoints können Sie jede HTTP-basierte KI-Anwendung mit elluminate verbinden — sei es Ihr eigener Modell-Server, ein Fine-Tuned Deployment, eine RAG-Pipeline, ein agentisches System oder ein beliebiger Service, der Prompts akzeptiert und Text zurückgibt. Sobald konfiguriert, kann Ihr Custom Endpoint in jedem Experiment verwendet werden, genau wie ein eingebauter Provider.
Custom Endpoint einrichten¶
Wählen Sie Custom API als Inference Type, dann füllen Sie die Base URL und den API Key für Ihren Endpunkt aus. Die Base URL muss den vollständigen Pfad zu Ihrem Endpunkt enthalten (z.B. https://your-api.example.com/v1/chat) — elluminate sendet Requests direkt an diese URL, ohne einen Pfad anzuhängen. Die Hauptkonfiguration erfolgt im API Configuration Template — einem JSON-Editor, in dem Sie definieren, wie elluminate mit Ihrer API kommuniziert.
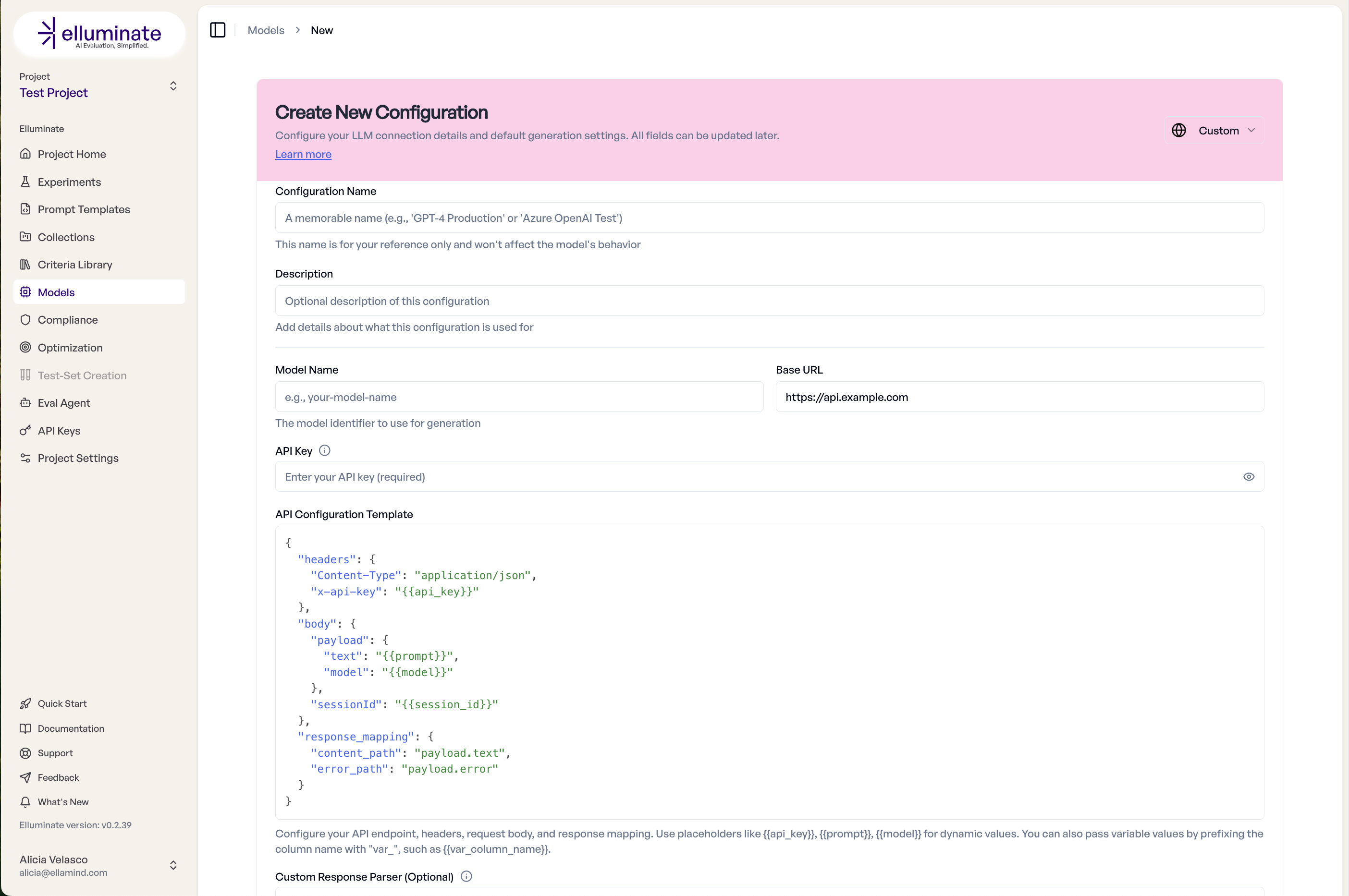
Das Template hat drei erforderliche Abschnitte:
Headers¶
HTTP-Header, die bei jeder Anfrage mitgesendet werden. Verwenden Sie Platzhalter für dynamische Werte:
Body¶
Der JSON-Request-Body. Unterstützt Platzhalter und verschachtelte Strukturen. Verwenden Sie {{prompt}} für Single-Turn oder {{messages}} für Multi-Turn-Konversationen:
Response Mapping¶
Definiert, wo elluminate den Inhalt in der JSON-Antwort Ihrer API findet:
| Schlüssel | Erforderlich | Beschreibung |
|---|---|---|
content_path |
Ja | Punkt-Notation-Pfad zum Response-Inhalt. Unterstützt Listen-Indizes (z.B. data.response, choices.0.message.content). |
error_path |
Nein | Punkt-Notation-Pfad zu Fehlermeldungen (z.B. error.message) |
Verfügbare Platzhalter¶
Verwenden Sie die {{placeholder_name}}-Syntax in Headers und Body. Diese werden vor jeder Anfrage durch die tatsächlichen Werte ersetzt:
| Platzhalter | Beschreibung |
|---|---|
{{api_key}} |
Der für diese LLM-Konfiguration konfigurierte API Key |
{{prompt}} |
Der Inhalt der ersten User-Nachricht (für Single-Turn-Anwendungsfälle) |
{{last_message}} |
Der Inhalt der letzten User-Nachricht (für zustandsbehaftete Bots, die nur den aktuellen Turn erwarten) |
{{messages}} |
Vollständiges Konversations-Array mit System-, User- und Assistant-Nachrichten (für Multi-Turn) |
{{model}} |
Der Modellname aus der Konfiguration |
{{base_url}} |
Die konfigurierte Base URL |
{{timestamp}} |
Aktueller Unix-Timestamp |
{{uuid}} |
Ein eindeutiger Request-Identifier (UUID v4) |
{{session_id}} |
Ein Session-Identifier im Format elluminate-<uuid>. Bei Stateful-Konfigurationen bleibt er über alle Turns einer Persona-Konversation hinweg stabil |
{{var_<name>}} |
Template-Variable-Werte aus Ihrer Collection, mit dem Präfix var_ (z.B. {{var_user_id}} für eine Variable namens user_id) |
Typerhaltung
Wenn ein Platzhalter der gesamte Wert eines Feldes ist (z.B. "{{messages}}"), wird der ursprüngliche Typ beibehalten — Listen bleiben Listen, Dicts bleiben Dicts. Wenn ein Platzhalter in einen String eingebettet ist (z.B. "Bearer {{api_key}}"), wird Standard-String-Interpolation verwendet.
Multi-Turn-Konversationen¶
Für APIs, die Multi-Turn-Konversationen unterstützen, verwenden Sie {{messages}}, um das vollständige Konversations-Array zu übergeben:
{
"headers": {
"X-API-Key": "{{api_key}}",
"Content-Type": "application/json"
},
"body": {
"conversation": "{{messages}}",
"model": "{{model}}"
},
"response_mapping": {
"content_path": "response.text"
}
}
Das {{messages}}-Array enthält Nachrichten im OpenAI-Format mit role- und content-Feldern.
Stateful APIs¶
Manche externen Bots (z.B. Cognigy) halten den Konversationszustand auf ihrer Seite, verknüpft mit einem Session-Identifier. Setzen Sie für solche Bots den optionalen Top-Level-Schlüssel "stateful": true in der Konfiguration (auf derselben Ebene wie headers, body und response_mapping).
In Persona-Multi-Turn-Experimenten ändert eine Stateful-Konfiguration zwei Dinge:
{{session_id}}wird einmal pro Konversation generiert (im Formatelluminate-eval-<uuid>) und bleibt über alle Turns hinweg stabil, sodass der externe Bot seinen Session-Zustand behält.- Pro Turn wird nur die letzte User-Nachricht gesendet (verwenden Sie
{{last_message}}im Body) statt der vollständigen Historie — der Bot kennt die vorherigen Turns aus seinem eigenen Session-Zustand. Folglich wird ein für das Experiment konfigurierter Bot-System-Prompt nicht an einen zustandsbehafteten Bot gesendet.
{
"headers": {
"X-API-Key": "{{api_key}}",
"Content-Type": "application/json"
},
"body": {
"sessionId": "{{session_id}}",
"text": "{{last_message}}"
},
"response_mapping": {
"content_path": "text"
},
"stateful": true
}
Außerhalb von Persona-Multi-Turn-Experimenten wird wie gewohnt pro Anfrage ein neuer {{session_id}} generiert.
Custom Response Parser¶
Für APIs mit nicht-standardisierten Response-Formaten können Sie einen Custom Response Parser bereitstellen — ein Python-Code-Snippet, das die rohe API-Antwort in das von elluminate erwartete Format transformiert.

Die content_path-Extraktion liefert immer einen String (Nicht-String-Werte werden JSON-serialisiert). Um eine Liste von Nachrichten zu erhalten (siehe Response-Verarbeitung Schritte 5–6), muss Ihr Parser eine Liste zurückgeben.
Der Parser erhält raw_response (ein String) und hat Zugriff auf die Module json und re (vorimportiert). Ihr Code muss die Variable parsed_response mit dem Endergebnis setzen (String oder Liste). Der Parser ist auf 5.000 Zeichen und 2 Sekunden Ausführungszeit begrenzt.
Beispiel: Ein agentisches System verbinden¶
Angenommen, Sie haben einen RAG-Agenten und möchten nicht nur die finale Antwort evaluieren, sondern den gesamten Ausführungs-Trace — Tool Calls, Retrieval-Schritte und Reasoning. So richten Sie es ein:
API Configuration Template:
{
"headers": {
"Authorization": "Bearer {{api_key}}",
"Content-Type": "application/json"
},
"body": {
"messages": "{{messages}}",
"config": {
"temperature": 0.2,
"return_trace": true,
"reasoning_effort": "high"
}
},
"response_mapping": {
"content_path": "trace"
}
}
Custom Response Parser:
So funktioniert es:
body.messagesübergibt die vollständige Konversation über{{messages}}an den Agenten.body.configsendet zusätzliche Optionen, die Ihr Endpunkt benötigt.response_mapping.content_pathzeigt auf das Trace-Objekt im Response-JSON.- Custom Response Parser extrahiert die Nachrichtensequenz aus dem serialisierten Trace, damit elluminate sie als Konversation darstellt.
Response-Verarbeitung¶
elluminate verarbeitet Custom-API-Antworten wie folgt:
- Die API-Antwort wird als JSON geparst. Falls das Parsing fehlschlägt, wird der Rohtext als
{"text": "<rohe Antwort>"}verpackt. - Der
content_pathextrahiert den Response-Inhalt aus dem JSON. - Falls ein
custom_response_parserkonfiguriert ist, wird er auf den extrahierten Inhalt angewendet. - Falls der
error_pathkonfiguriert ist und einen Wert enthält, wird dieser als Warnung protokolliert. - Wenn der finale Inhalt eine Liste ist, wird er als Liste von Message-Objekten behandelt (jeweils mit
role- undcontent-Feldern). - Wenn der finale Inhalt ein String ist, wird er als Assistant-Nachricht verpackt.
Einschränkungen¶
- Nur
POST-Requests werden unterstützt — der Endpunkt muss einen 2xx-Statuscode zurückgeben - Streaming wird nicht unterstützt
- Token-Usage-Metriken (Input-/Output-Tokens) sind für Custom Endpoints nicht verfügbar
- Structured Outputs und Tool Calling werden nicht unterstützt
- Der Connect- und Read-Timeout beträgt standardmäßig 60 Sekunden (konfigurierbar über das
timeout-Feld der LLM-Konfiguration)
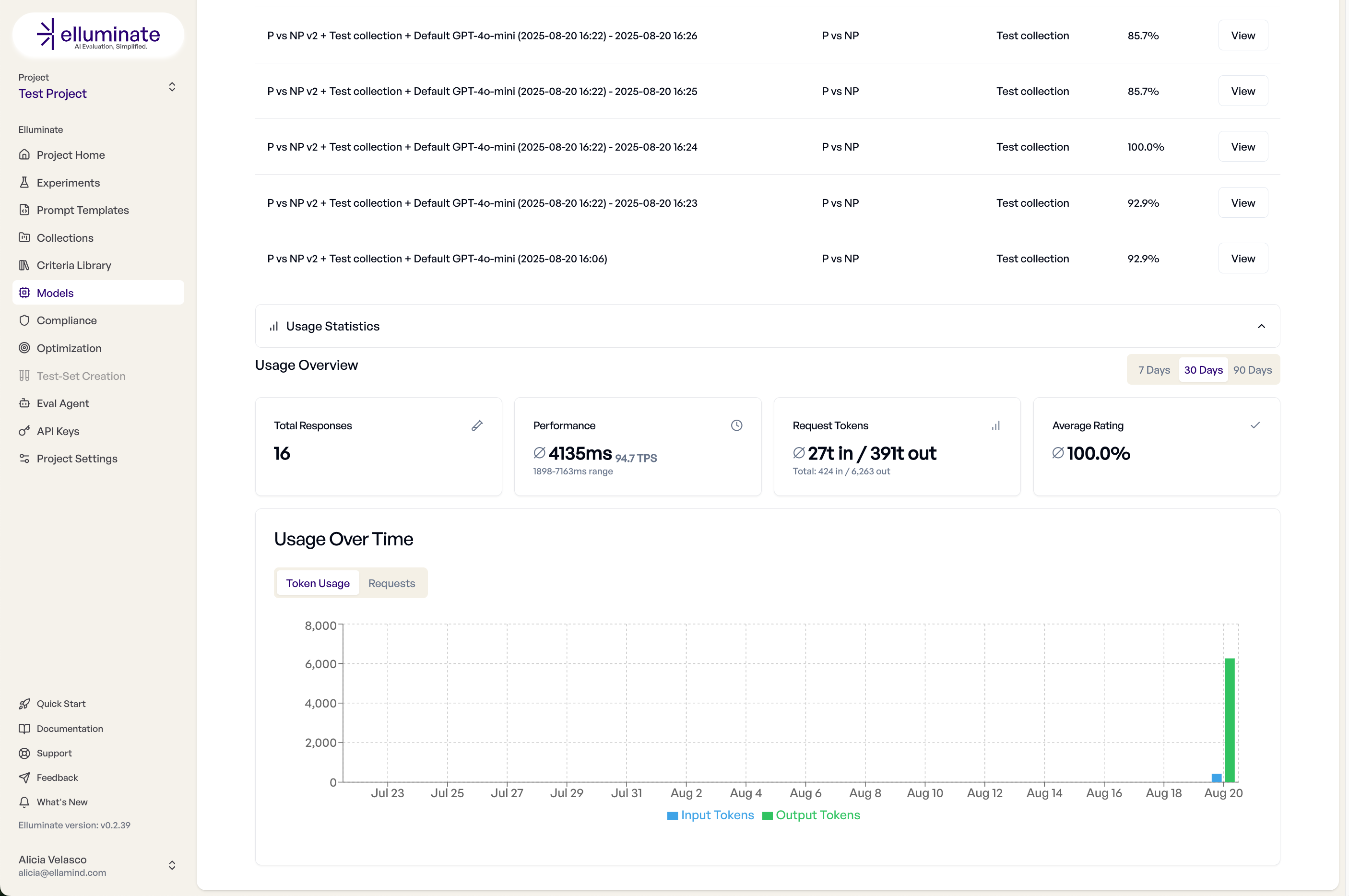
Monitoring und Analyse¶
Verfolgen Sie die Nutzung einer Modellkonfiguration — durchgeführte Experimente und Leistungsmetriken — in der Konfigurationsdetailansicht.
SDK-Integration¶
Alle in der UI erstellten Konfigurationen können auch über das SDK verwaltet werden. Verwenden Sie get_or_create_llm_config für idempotentes Setup:
performance_config, created = client.get_or_create_llm_config(
name="Fast Response Model",
defaults={
"llm_model_name": "gpt-4o-mini",
"api_key": "key",
"inference_type": InferenceType.OPENAI,
# Performance settings
"max_tokens": 500, # Limit response length
"temperature": 0.3, # More deterministic
"top_p": 0.9, # Nucleus sampling
"max_connections": 20, # Parallel requests
"timeout": 10, # Fast timeout in seconds
"max_retries": 2, # Limited retries
"description": "Optimized for quick responses",
},
)
Custom API Endpoints folgen derselben Struktur — übergeben Sie custom_api_config und optional custom_response_parser:
custom_config, created = client.get_or_create_llm_config(
name="My Custom Model v2",
defaults={
"llm_model_name": "custom-model-v2",
"api_key": "your-api-key",
"llm_base_url": "https://api.mycompany.com/v1",
"inference_type": InferenceType.CUSTOM_API,
"custom_api_config": {
"headers": {
"Authorization": "Bearer {{api_key}}",
"Content-Type": "application/json",
"X-Model-Version": "{{model}}",
},
"body": {"prompt": "{{prompt}}", "max_tokens": 1000, "temperature": 0.7, "stream": False},
"response_mapping": {"content_path": "data.response", "error_path": "error.message"},
},
"description": "Our production recommendation model",
},
)
Best Practices¶
Konfigurationsstrategie¶
- Development: Verwenden Sie günstigere, schnellere Modelle
- Staging: Testen Sie mit Produktionsmodellen
- Production: Optimieren Sie Parameter für Ihren Anwendungsfall
- Monitoring: Richten Sie Ihre eigenen Endpunkte für Transparenz ein
Custom API Best Practices¶
- Response-Format standardisieren: Verwenden Sie konsistente JSON-Strukturen über Endpunkte hinweg
- Metadaten einbeziehen: Geben Sie Modellversion, Latenz und Konfidenz zurück
- Fehlerbehandlung: Liefern Sie klare Fehlermeldungen über den
error_path - Rate Limiting: Implementieren Sie angemessenes Throttling auf Ihrem Endpunkt
- Monitoring: Protokollieren Sie alle Anfragen für Analysen
Troubleshooting¶
Häufige Probleme¶
Verbindung fehlgeschlagen
- Überprüfen Sie, ob der API Key gültig ist
- Überprüfen Sie das Base URL Format (muss mit
http://oderhttps://beginnen) - Stellen Sie die Netzwerkverbindung sicher
- Prüfen Sie die Firewall-Regeln
Langsame Antworten
- Reduzieren Sie max_tokens
- Senken Sie die Temperature
- Überprüfen Sie die API Rate Limits
- Überdenken Sie die Modellgröße
Inkonsistente Ergebnisse
- Senken Sie die Temperature für Determinismus
- Setzen Sie den Seed-Parameter, falls verfügbar
- Verwenden Sie konsistente System Prompts
- Überprüfen Sie die Modellversion