Experimente¶
Lernen Sie, Ihre LLM-Anwendungen systematisch zu testen und zu vergleichen
Experimente helfen Ihnen dabei, verschiedene Prompts systematisch zu vergleichen, ihre Effektivität zu bewerten und die Leistung im Zeitverlauf zu verfolgen. Sie sind die Grundlage für datengetriebene LLM-Entwicklung und ermöglichen es Ihnen, mehrere Varianten zu testen und zu analysieren, welche für Ihren spezifischen Anwendungsfall am besten funktioniert.
Was ist ein Experiment?¶
Ein Experiment kombiniert mehrere Schlüsselkomponenten, um eine systematische Evaluierung zu erstellen:
- Collection - Eine Reihe von Test-Eingaben (Template-Variablen), die verschiedene Szenarien repräsentieren
- Prompt Template - Die Grundlage mit Ihrem Prompt und
{{Variablen}} - LLM Config - Die Modellkonfiguration (Anbieter, Parameter, etc.)
- Criterion Set - Evaluationskriterien, die definieren, was eine gute Antwort ausmacht
Wenn Sie ein Experiment ausführen, generiert elluminate Antworten für jede Eingabe in Ihrer Collection und evaluiert dann automatisch jede Antwort anhand Ihrer Kriterien.
Welche dieser Komponenten Sie konfigurieren, hängt vom gewählten Experimenttyp ab. Ein normaler Generieren & Evaluieren-Lauf nutzt alle vier, während Importierte Antworten bewerten das Prompt Template und das Modell komplett überspringt und bereits vorhandene Antworten bewertet. Eine vollständige Übersicht finden Sie unter Experimenttyp wählen.
Ihr erstes Experiment erstellen¶
Schritt 1: Zu Experimenten navigieren¶
Gehen Sie in Ihrem Projekt zur Experiments-Seite. Sie sehen Ihre Liste der Experimentausführungen mit Optionen zum Erstellen neuer Experimente oder zum Anzeigen der Timeline.
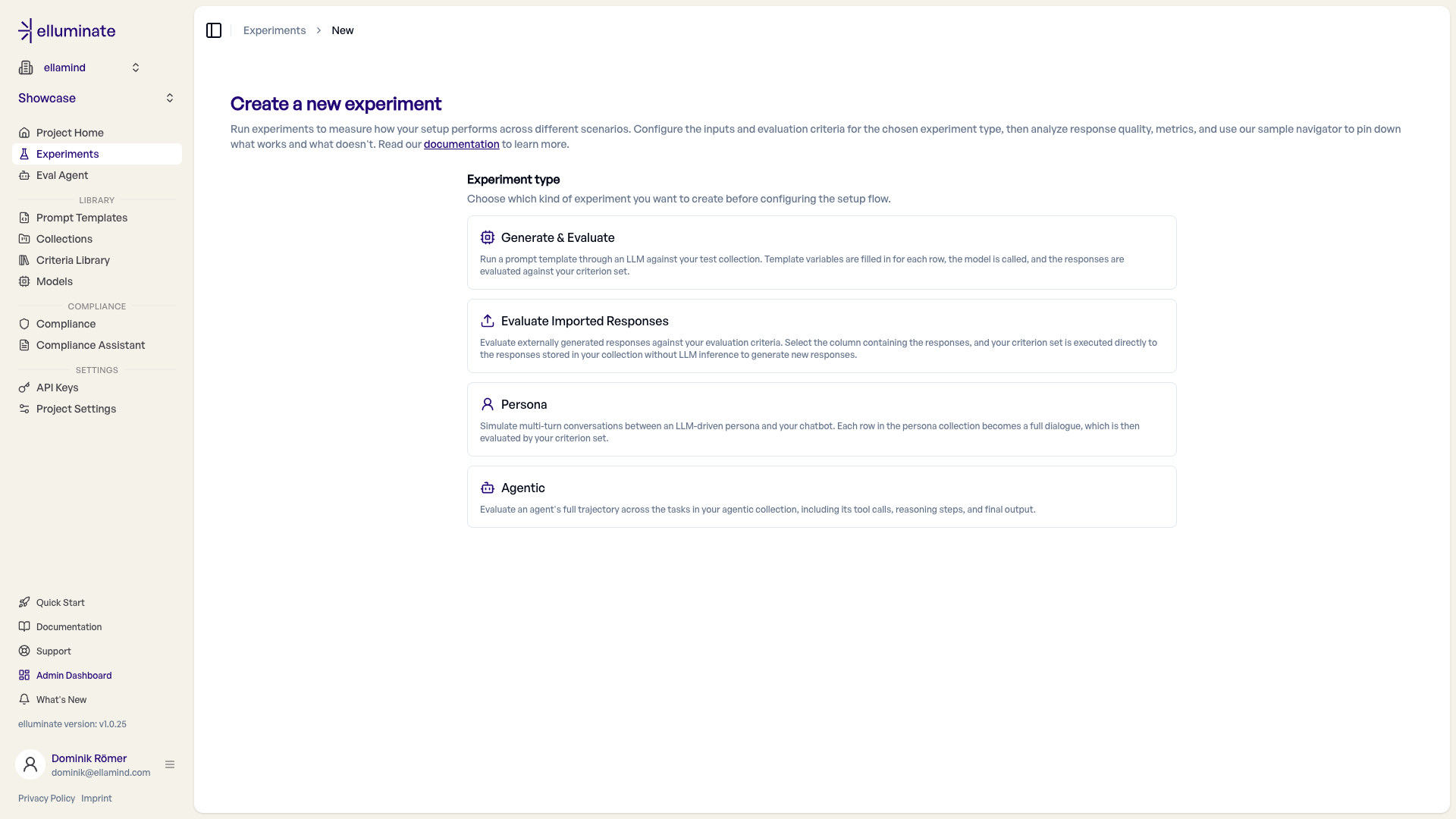
Schritt 2: Experimenttyp wählen¶
Klicken Sie auf "New Experiment". elluminate fragt zuerst, welche Art von Experiment Sie erstellen möchten. Das anschließende Setup ist typabhängig — es zeigt nur die Schritte, die für den gewählten Typ relevant sind.
| Experimenttyp | Beschreibung | Setup-Schritte |
|---|---|---|
| Generieren & Evaluieren | Lässt ein Prompt Template durch ein LLM gegen Ihre Collection laufen. Die Variablen werden für jede Zeile gefüllt, das Modell wird aufgerufen, und die Antworten werden anhand Ihrer Kriterien bewertet. | Collection → Prompt Template → Modell → Kriterien |
| Importierte Antworten bewerten | Bewertet extern generierte Antworten, die bereits in Ihrer Collection gespeichert sind. Ihre Kriterien werden direkt darauf angewendet — ohne LLM-Inferenz. | Collection → Antwortspalte → Kriterien |
| Persona | Simuliert mehrstufige Konversationen zwischen LLM-gesteuerten Personas und Ihrem Chatbot. Jede Persona der Group wird gegen jede Zeile der Question Library ausgeführt, und jeder entstehende Dialog wird bewertet. | Persona Group → Question Library → Prompt Template → Modell → Kriterien |
| Agentic | Bewertet die gesamte Trajektorie eines Agenten über die Tasks in Ihrer Collection, einschließlich seiner Tool-Aufrufe, Reasoning-Schritte und finalen Ausgabe. | Collection → Prompt Template → Modell → Kriterien |
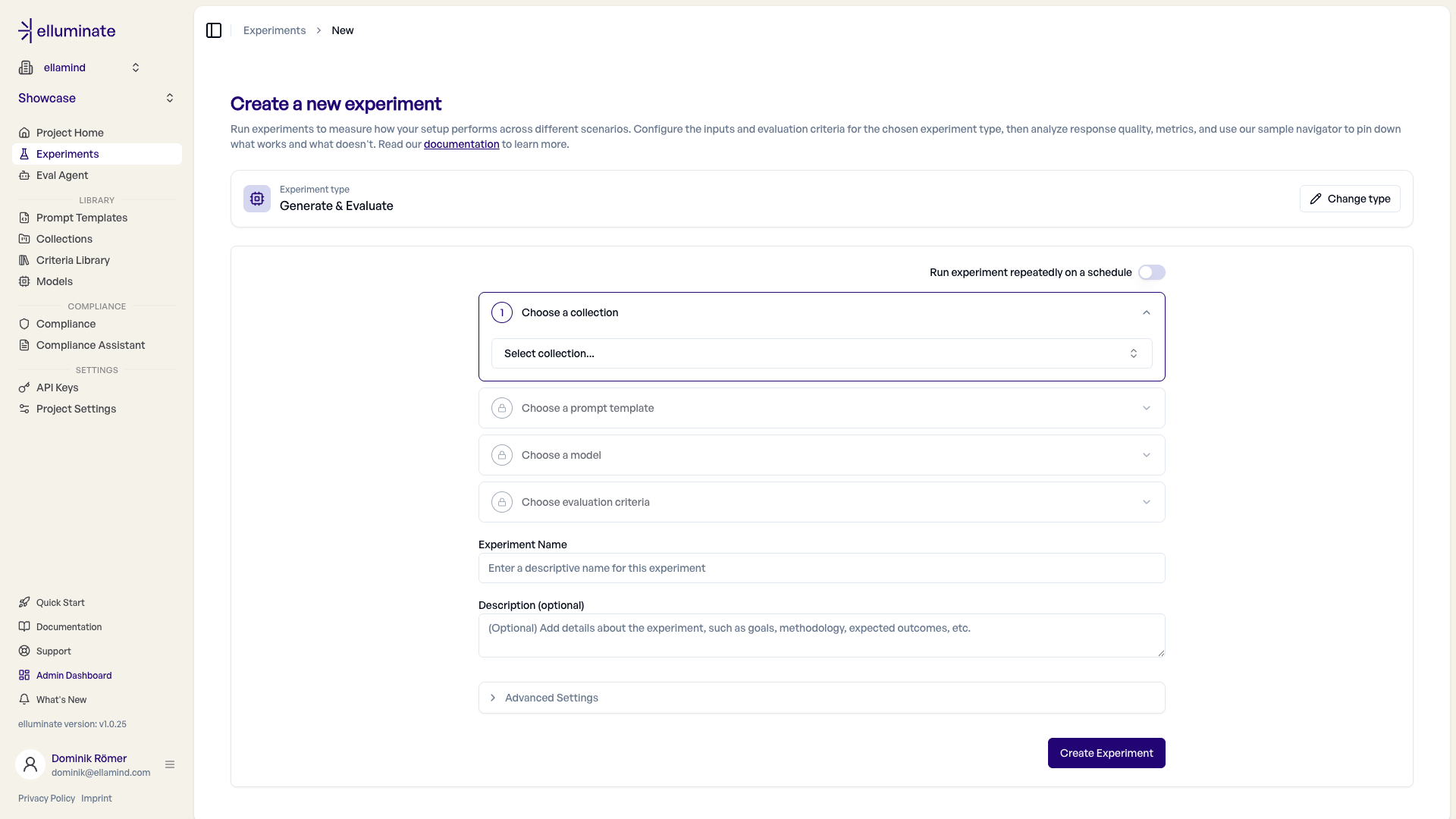
Nach der Auswahl wird der Typ zu einer Zusammenfassungszeile reduziert; über "Typ ändern" können Sie jederzeit wechseln.
Typspezifische Collections
Persona- und Agentic-Experimente benötigen einen passenden Collection-Typ (Persona bzw. Agentic), während Generieren & Evaluieren und Importierte Antworten bewerten Standard-Collections verwenden. Der Typ Agentic ist nur in Nicht-Produktionsumgebungen verfügbar, solange der Workflow finalisiert wird.
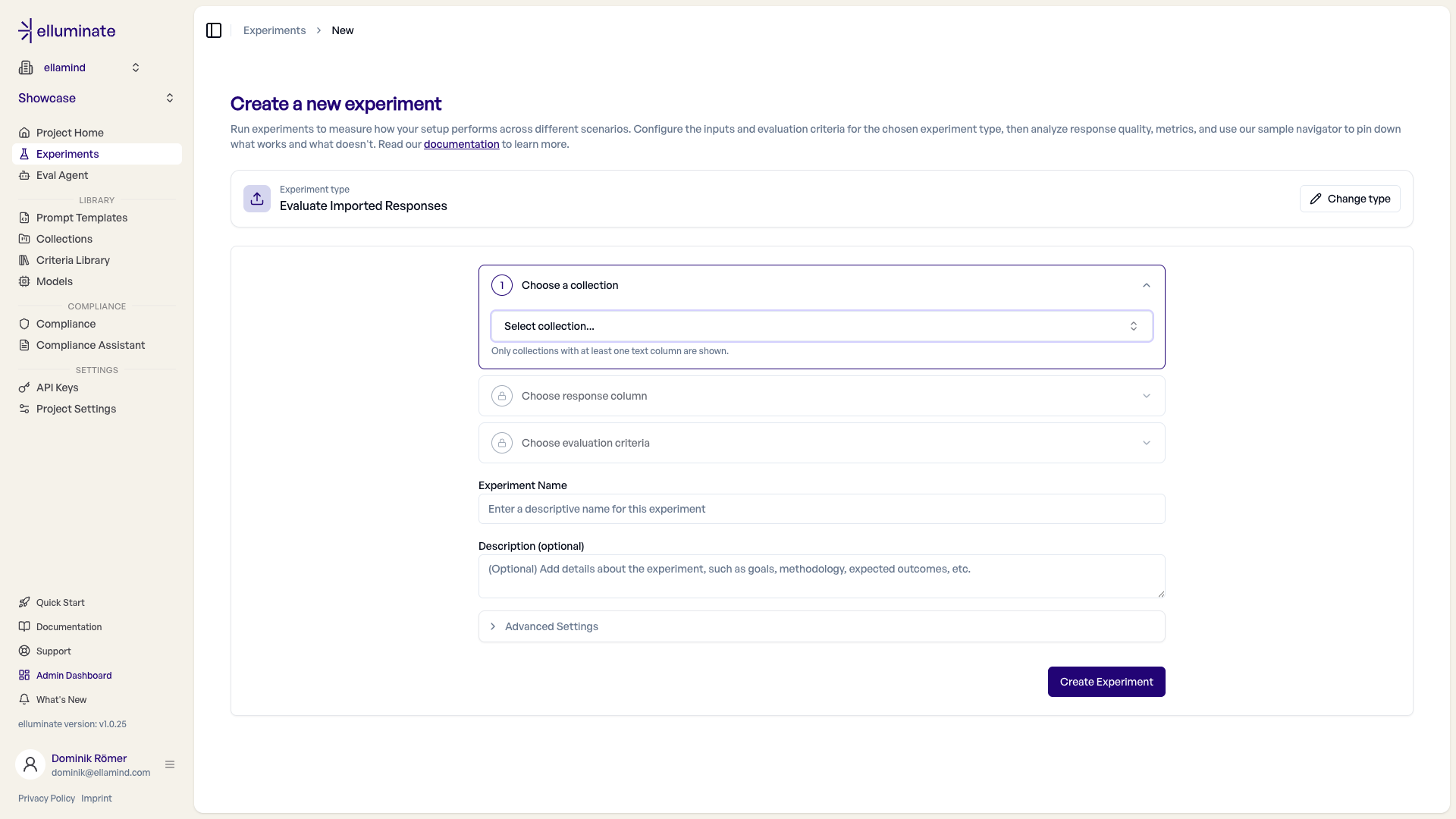
Schritt 3: Den Setup-Flow konfigurieren¶
elluminate führt Sie durch ein Schritt-Akkordeon — Schritt für Schritt, wobei jeder Schritt den nächsten freischaltet. Abgeschlossene Schritte werden zu einer Zusammenfassung reduziert, die Sie zum Ändern einer Auswahl wieder öffnen können. Für ein Generieren & Evaluieren-Experiment lauten die Schritte:
- Collection wählen - Ihr Test-Eingaben-Datensatz.
- Prompt Template wählen - Das versionierte Template mit
{{Variablen}}. Optional, wenn die Collection bereits vollständige Prompts enthält (eine Conversation- oder Raw-Input-Spalte). - Modell wählen - Die LLM-Config, die zur Antwortgenerierung verwendet wird.
- Bewertungskriterien wählen - Das Criterion Set, anhand dessen die Antworten bewertet werden.
Unterhalb des Akkordeons legen Sie den Experiment Name und eine optionale Beschreibung fest.
Kompatibilitätsregeln
Das System bietet nur gegenseitig kompatible Collections, Prompt Templates und Criterion Sets an. Wenn Ihre gewünschte Auswahl nicht erscheint, überprüfen Sie Ihre Platzhalter und Spaltenbenennung auf Probleme.
Erweiterte Einstellungen
- Rating Mode - Der Detailed-Modus enthält Begründungen für jedes Kriterium und wird für bessere Interpretierbarkeit empfohlen. Der Fast-Modus liefert nur Bewertungen ohne Erklärungen und kann etwas schneller sein.
- Epochs - Epochs ermöglichen es, dieselbe Evaluierung mehrfach auszuführen. Dies macht die Statistiken zuverlässiger, kann aber einige Zeit in Anspruch nehmen.
- Rating Version - Wählen Sie die Rating-Modell-Version zur Bewertung der Antworten. Standardmäßig wird die in Ihren Projekteinstellungen festgelegte Version verwendet.
Schritt 4: Das Experiment ausführen¶
Nach dem Klicken auf "Create Experiment" wird elluminate:
- Antworten generieren - LLM-Antworten für jede Test-Eingabe erstellen (entfällt bei Importierte Antworten bewerten, das die bereits in Ihrer Collection vorhandenen Antworten verwendet)
- Antworten bewerten - Jede Antwort anhand Ihrer Kriterien evaluieren
- Ergebnisse berechnen - Gesamtscores und Kriterien-Performance berechnen
Sie können den Fortschritt in Echtzeit von der Experiment-Detailseite aus überwachen.
Importierte Antworten bewerten¶
Wenn Sie bereits Modellausgaben haben — aus einem Produktivsystem, einem anderen Tool oder einem früheren Lauf — können Sie diese direkt bewerten, ohne etwas neu zu generieren. Wählen Sie den Typ Importierte Antworten bewerten und folgen Sie dem dreistufigen Flow:
- Collection wählen - Es werden nur Collections mit mindestens einer Textspalte angezeigt.
- Antwortspalte wählen - Die Textspalte, die die zu bewertenden Ausgaben enthält.
- Bewertungskriterien wählen - Das Criterion Set, das auf diese Antworten angewendet wird.
elluminate wendet Ihre Kriterien direkt auf die gespeicherten Antworten an — ohne Prompt Template, Modell oder LLM-Inferenz. Das macht diesen Typ ideal für das Benchmarking externer Systeme oder die Bewertung anderswo gesammelter Antworten.
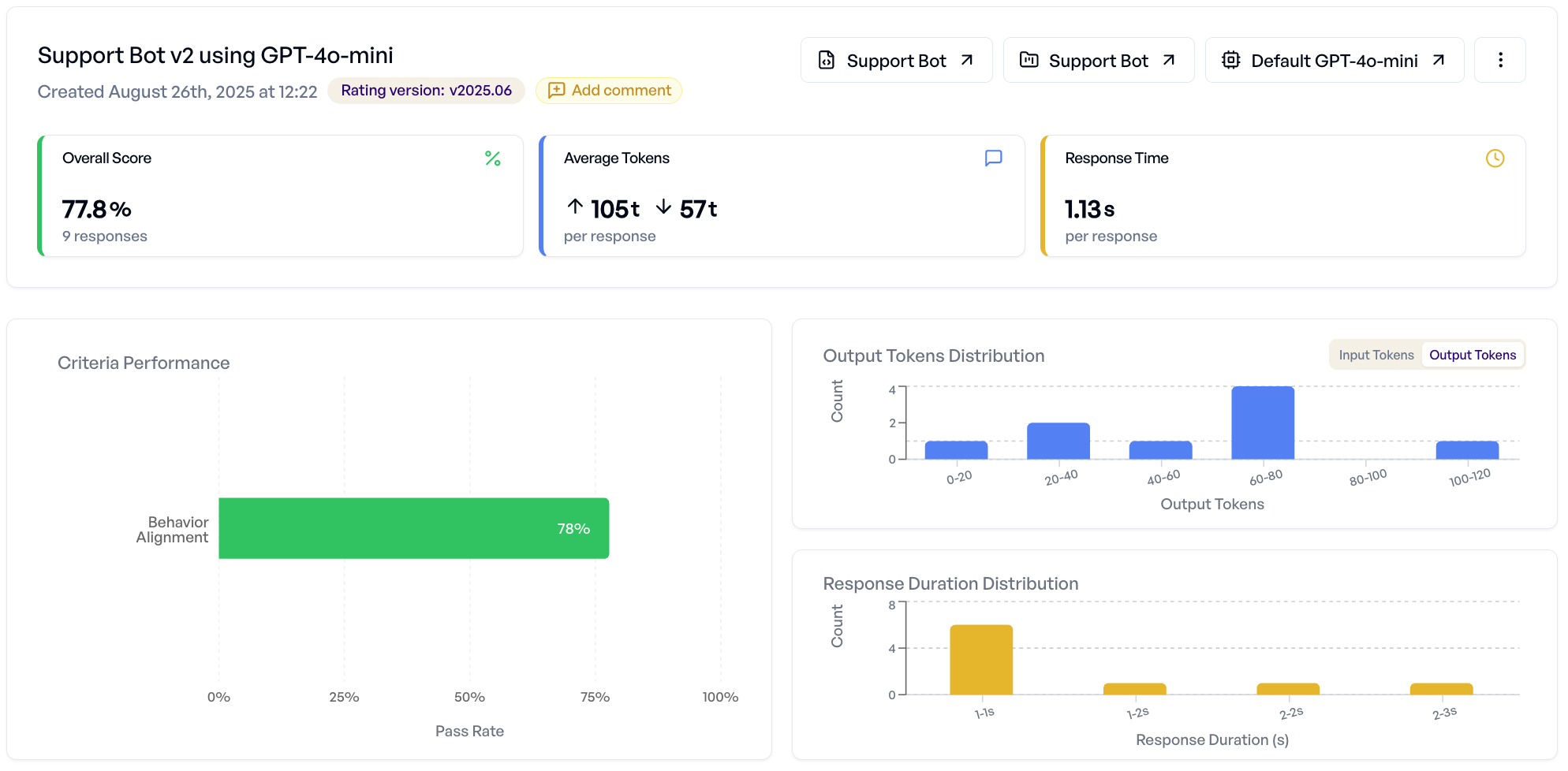
Experimentergebnisse verstehen¶
Sobald Ihr Experiment abgeschlossen ist, können Sie die Ergebnisse in zwei Hauptansichten analysieren:
Tab "Detailed Analysis"¶
Dieser Tab bietet aggregierte Einblicke und die Inspektion von einzelnen Antworten:
- Overall Score - Erfolgsraten, Score-Verteilungen, Token-Verbrauch
- Criterion Breakdown - Welche Kriterien am häufigsten bestehen/nicht bestehen
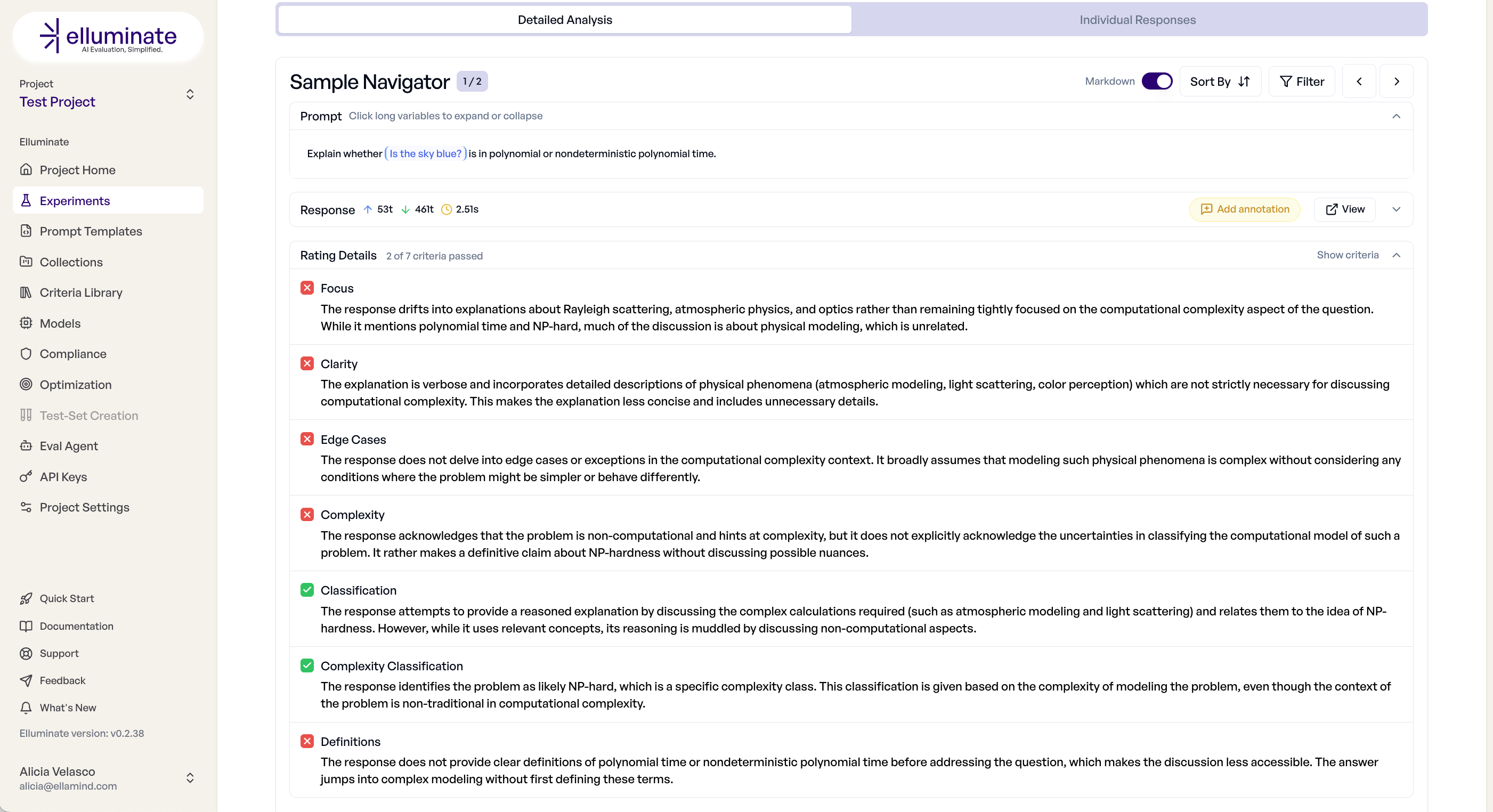
- Sample Navigator - Durchsuchen einzelner Antworten mit vollständigen Bewertungsdetails
- Performance-Charts - Visuelle Analyse von Score-Mustern und Verteilungen
Tab "Individual Responses"¶
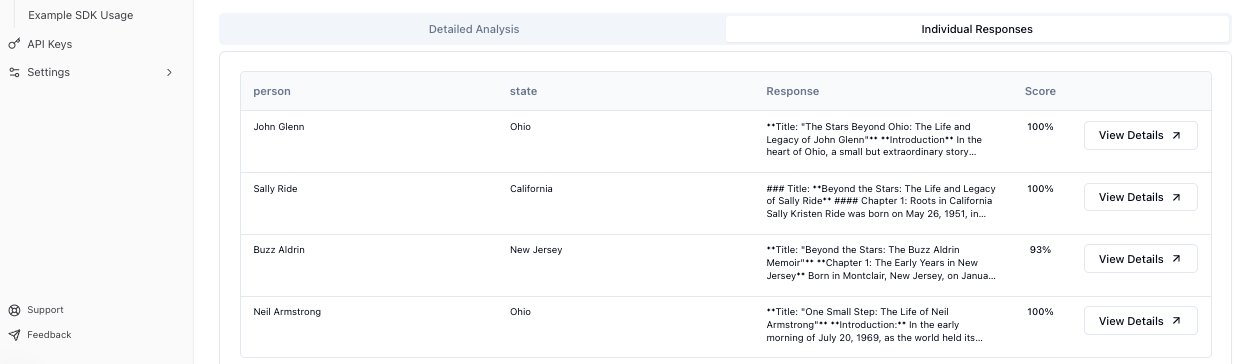
Dieser Tab bietet eine tabellarische Ansicht aller Ergebnisse:
- Antwort-Tabelle - Sortierbare Liste aller Prompt-Antwort-Paare
- Bewertungsdetails - Bestanden/Nicht-bestanden-Status für jedes Kriterium pro Antwort
- Export-Optionen - Ergebnisse als CSV mit vollständigen Daten herunterladen
- Filtern - Fokus auf bestimmte Score-Bereiche oder Kriterien-Ergebnisse
Für detaillierte Analysetechniken siehe den Response Analyse Guide.
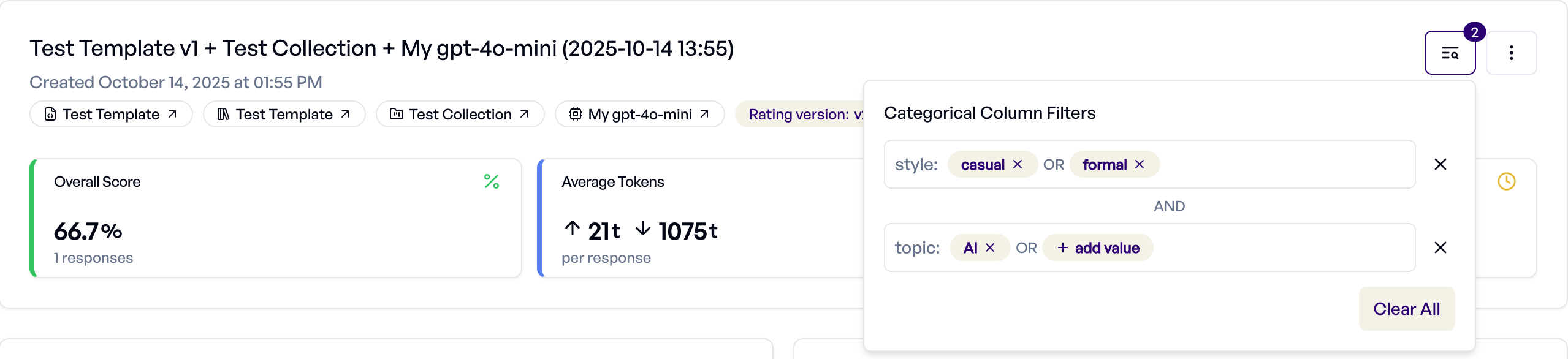
Filtern nach Kategorie-Spalten¶
Wenn Ihre Collection Spalten des Typs Kategorie enthält, können Sie Experiment-Antworten filtern, um die Leistung über verschiedene Kategorien hinweg zu analysieren.
Setup: Konfigurieren Sie Spalten als Kategorie-Typ in Ihrer Collection. Details finden Sie unter Collection-Spalten verwalten.
Verwendung:
- Klicken Sie oben rechts auf das Filter-Symbol
- Wählen Sie Kategorie-Spalten und Werte aus, die einbezogen werden sollen
- Mehrere Werte innerhalb einer Spalte verwenden ODER-Logik (zeigt Antworten, die mit einem beliebigen Wert übereinstimmen)
- Mehrere Spalten verwenden UND-Logik (zeigt Antworten, die alle Bedingungen erfüllen)
- Metriken und Diagramme werden aktualisiert, um nur gefilterte Antworten zu reflektieren
Dies ermöglicht gezielte Analysen - zum Beispiel das Filtern nach user_type als Enterprise oder SMB, um die Leistung über Kundensegmente hinweg zu vergleichen, oder region als US oder EU, um die regionale Effektivität zu analysieren.
Experimente vergleichen¶
elluminate unterstützt das Vergleichen von Experimenten, um Verbesserungen zu identifizieren und Leistungsänderungen zu verfolgen.
Zwei-Experiment-Vergleich¶
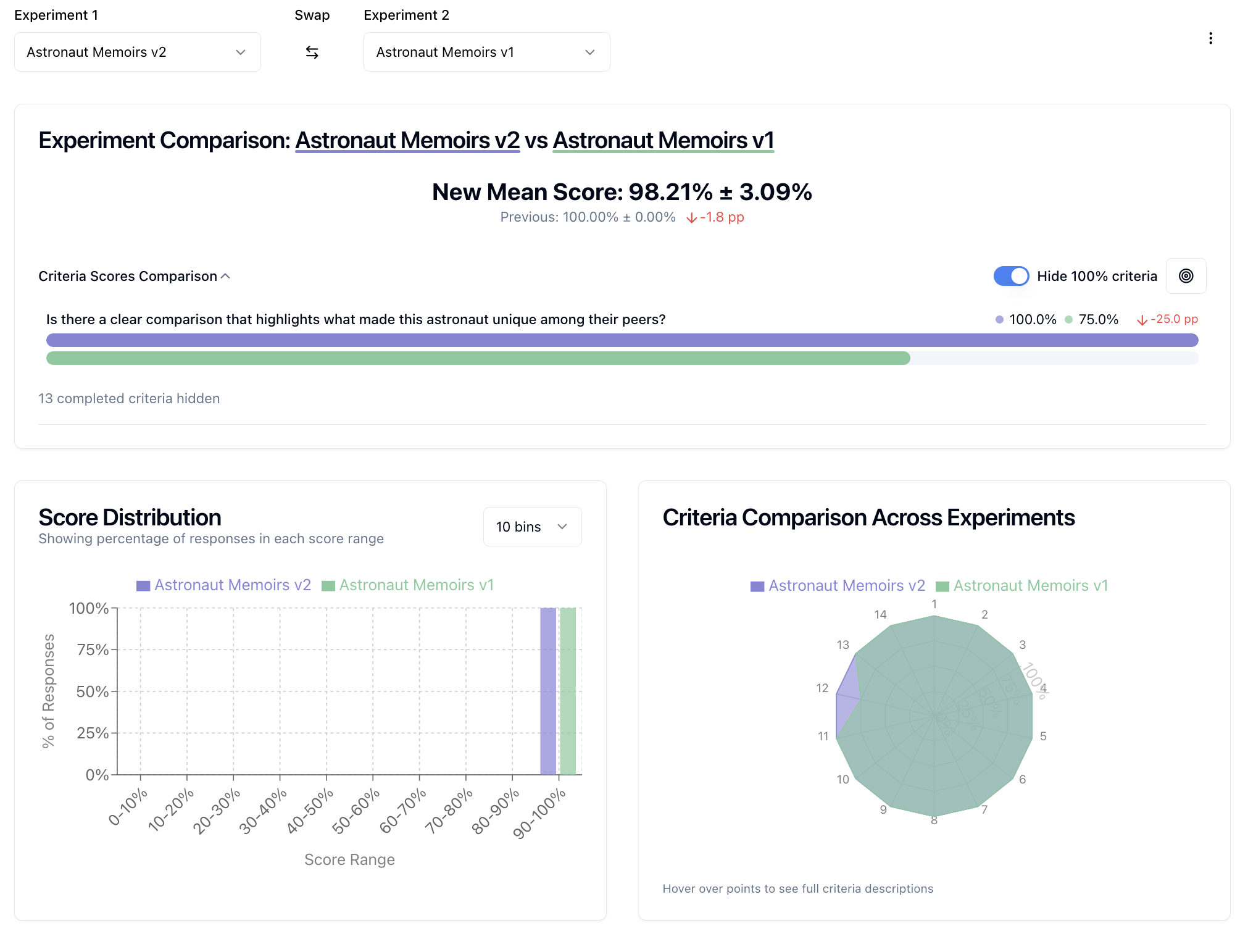
Vergleichen Sie zwei Experimente nebeneinander, um Unterschiede zu verstehen:
- Wählen Sie zwei Experimente aus Ihrer Liste
- Klicken Sie auf "Compare" für eine detaillierte Vergleichsansicht
- Analysieren Sie nebeneinander Antworten, Kriterien-Performance-Deltas und Gesamtscore-Änderungen
Multi-Experiment-Vergleich¶
Für einen Überblick über mehrere Experimente hinweg:
- Wählen Sie 3+ Experimente aus Ihrer Liste
- Nutzen Sie die Multi-Vergleichsansicht für aggregierte Performance-Trends
- Identifizieren Sie, welche Experimente bei verschiedenen Kriterien am besten abschneiden
Performance über Zeit überwachen¶
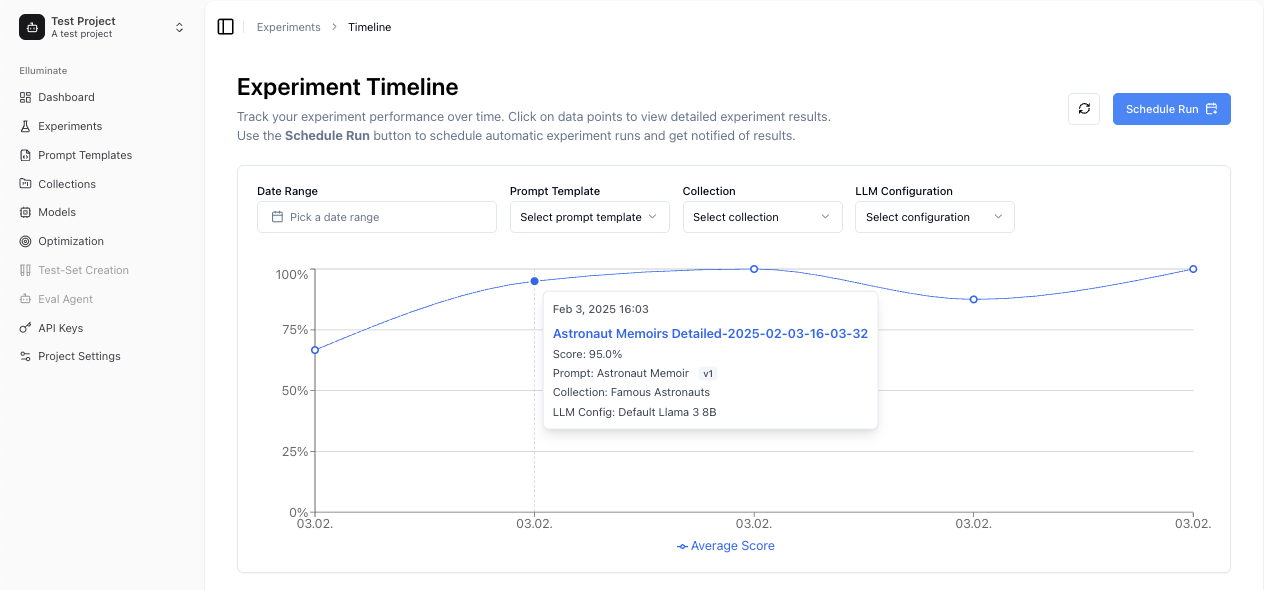
Timeline-Ansicht¶
Die Timeline bietet historische Performance-Verfolgung:
- Performance-Trends - Sehen Sie, wie Ihre Experimente über die Zeit abschneiden
- Filter-Optionen - Filtern Sie nach Zeitbereich, Prompt Template, Collection oder Modell
- Datenpunkt-Details - Darüberfahren für Experiment-Informationen, klicken für Detailansicht
Geplante Experimente¶
Es ist möglich, regelmäßige Evaluierungen mit geplanten Experimenten zu automatisieren.
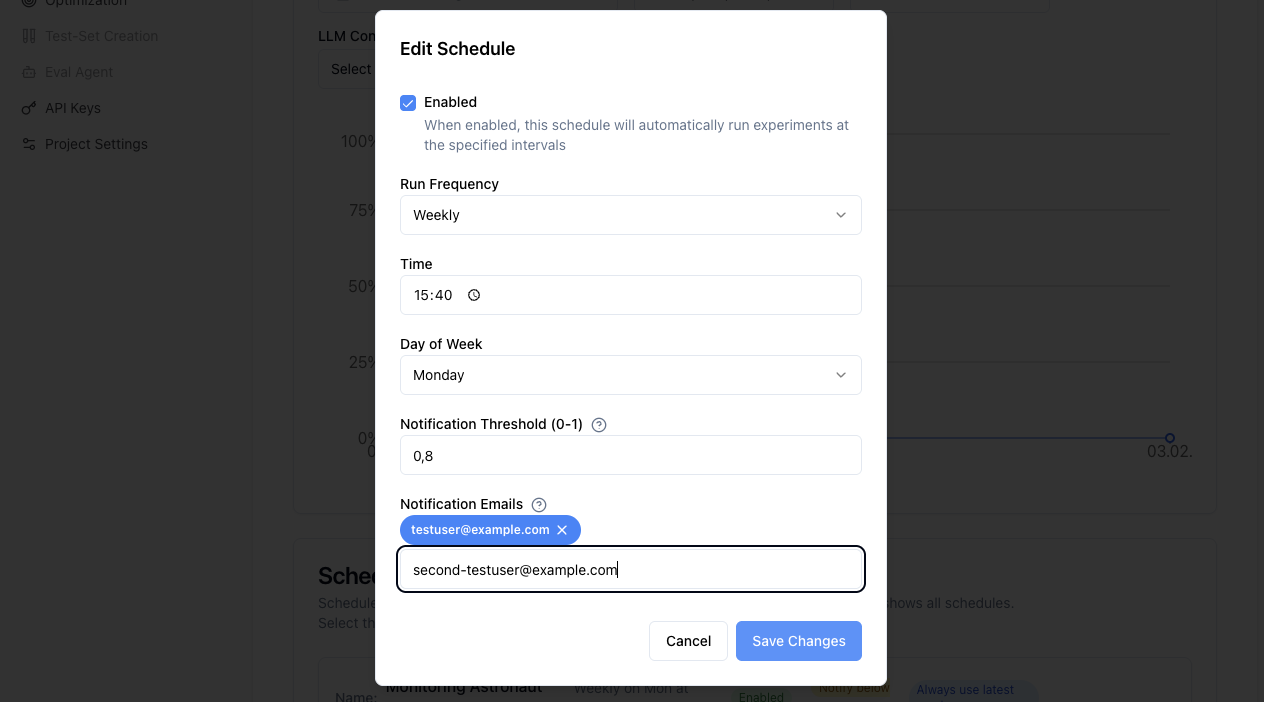
Zeitpläne erstellen:
- Klicken Sie in der Timeline-Ansicht auf "Schedule Run"
- Konfigurieren Sie Häufigkeit (täglich, wöchentlich, monatlich)
- Setzen Sie Experiment-Parameter (Template, Collection, Modell)
- Konfigurieren Sie Benachrichtigungen und Schwellenwerte
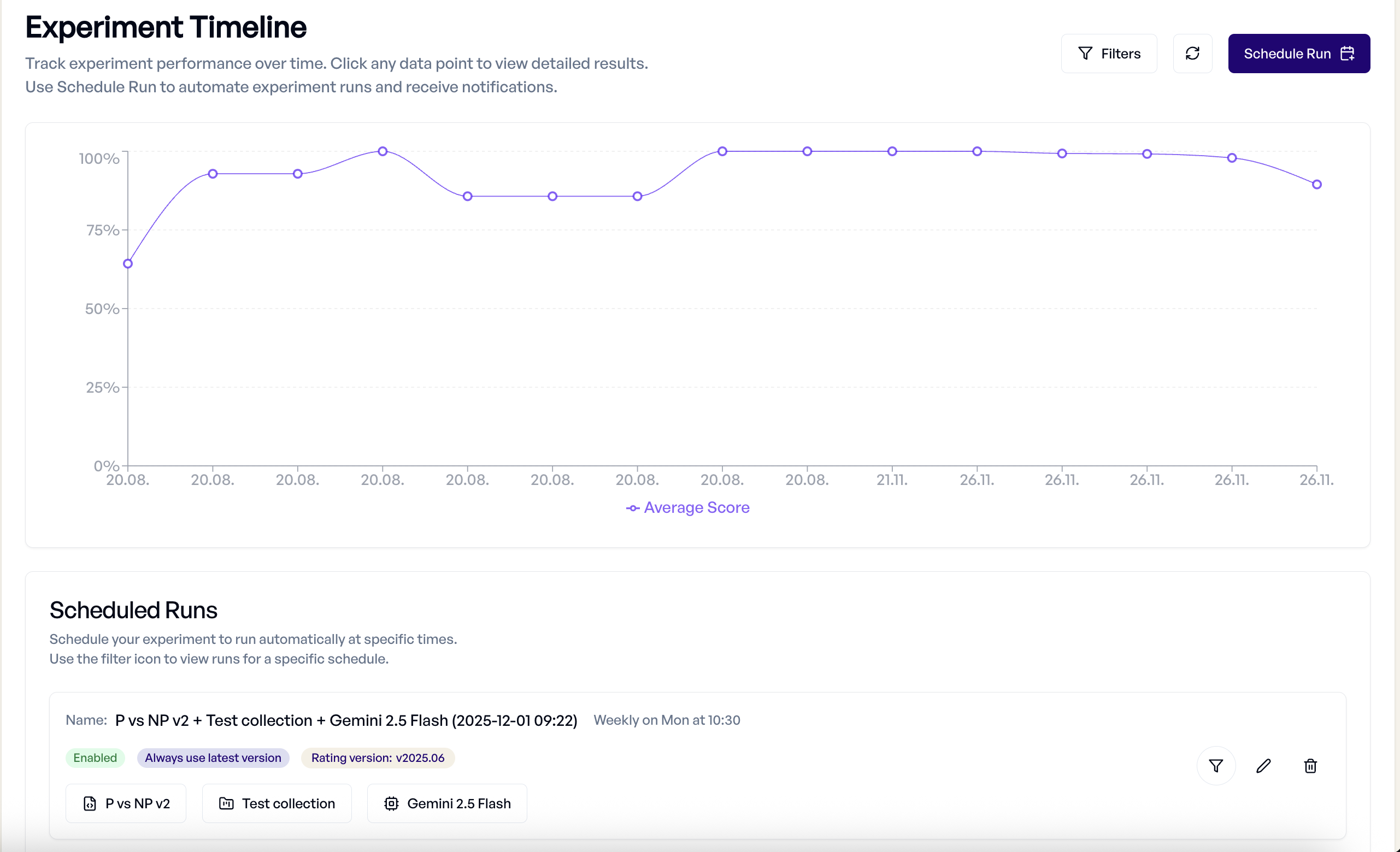
Zeitplan-Management:
Um Ihre Zeitpläne zu verwalten, navigieren Sie zur Timeline-Ansicht und scrollen Sie nach unten. Dort können Sie:
- Alle Zeitpläne anzeigen - Überwachen Sie aktive Zeitpläne und ihre Einstellungen mithilfe der Filterfunktion
- Zeitpläne bearbeiten - Häufigkeit und Schwellenwerte modifizieren oder Zeitpläne deaktivieren
- Zeitpläne löschen - Zeitpläne löschen, ohne die vorherigen Experimente zu verändern
Fortgeschrittene Features¶
Structured Outputs und Tool Calling¶
Experimente funktionieren nahtlos mit fortgeschrittenen LLM-Features:
- Structured Outputs - JSON-Antworten mit Schema-Validierungskriterien evaluieren
- Tool Calling - Tool-Nutzung und Parameter-Korrektheit in agentischen Anwendungen bewerten
- Multi-Step-Workflows - Komplexe Interaktionsmuster evaluieren
Für Details siehe Structured Outputs und Tool Calling.
Integration mit anderen Komponenten¶
Experimente nutzen Ihr gesamtes elluminate-Setup:
- Collections - Testdatensätze über verschiedene Experimente wiederverwenden
- Prompt Templates - Versionskontrolle gewährleistet Experiment-Reproduzierbarkeit
- Criterion Sets - Konsistente Evaluationsstandards anwenden
- LLM Configs - Verschiedene Modelle und Parameter systematisch testen
Best Practices¶
Experiment-Design¶
- Klare Ziele - Definieren Sie, was Sie testen, bevor Sie Experimente ausführen
- Repräsentative Daten - Stellen Sie sicher, dass Ihre Collection reale Szenarien abdeckt
- Geeignete Kriterien - Wählen Sie Evaluationskriterien, die zu Ihrem Anwendungsfall passen
- Kontrollierte Variablen - Ändern Sie jeweils nur eine Sache für klare Erkenntnisse
Performance-Optimierung¶
- Batch-Testing - Führen Sie mehrere Variationen zusammen für schnellere Iteration aus
- Strategisches Sampling - Nutzen Sie kleinere Collections für schnelles Prototyping
- Kostenmanagement - Nutzen Sie den Fast-Rating-Modus, wenn detaillierte Erklärungen nicht benötigt werden
- Historischer Kontext - Vergleichen Sie mit vorherigen Experimenten, um Verbesserungen zu verfolgen
Qualitätssicherung¶
- Manuelle Überprüfung - Stichproben der automatisierten Bewertungen auf Genauigkeit prüfen
- Edge-Case-Testing - Herausfordernde Szenarien in Ihre Collections einschließen
- Konsistente Evaluation - Gleiche Criterion Sets für vergleichbare Ergebnisse verwenden
- Dokumentation - Experimentziele und Erkenntnisse in Beschreibungen festhalten
SDK-Integration¶
Für programmatische Experiment-Erstellung und -Management können Sie das elluminate SDK verwenden:
from elluminate import Client
from elluminate.schemas import RatingMode
client = Client() # Nutzt ELLUMINATE_API_KEY env var
Für vollständige SDK-Dokumentation siehe die API-Referenz.
Troubleshooting¶
Häufige Probleme¶
- Generierungsfehler - LLM-Config-Einstellungen und Rate-Limits überprüfen
- Bewertungsfehler - Criterion Set-Kompatibilität mit Antwortformat verifizieren
- Performance-Probleme - Fast-Rating-Modus für große Collections verwenden
- Fehlende Ergebnisse - Vor der Analyse sicherstellen, dass das Experiment erfolgreich abgeschlossen wurde
Hilfe erhalten¶
Wenn Experimente nicht wie erwartet funktionieren:
- Logs überprüfen - Experiment-Logs auf spezifische Fehlermeldungen überprüfen
- Komponenten validieren - Prompt Templates und Collections unabhängig testen
- Einstellungen überprüfen - Prüfen, ob LLM-Config-Parameter geeignet sind
- Support kontaktieren - Mit Experiment-IDs für detaillierte Unterstützung