Personas¶
Evaluieren Sie Ihren Chatbot Ende-zu-Ende, indem wiederverwendbare, simulierte Nutzer ein Ziel über echte, mehrstufige Unterhaltungen hinweg verfolgen.
Eine Persona ist eine wiederverwendbare Definition eines simulierten Nutzers. In einem Persona-Experiment simuliert ein LLM jede Persona, während sie ein Ziel verfolgt. Der zu testende Bot bzw. LLM Endpoint antwortet Runde für Runde, und das entstandene Transkript wird als Ganzes anhand Ihres Criterion-Set bewertet. Personas leben in einer projektweiten Library, werden in Persona Groups organisiert und gegen eine Collection ausgeführt, sodass jede Persona gegen jedes Szenario in einem einzigen Experiment evaluiert wird.
Was es ist¶
Definieren Sie Personas einmal in der Library und verwenden sie über Experimente hinweg wieder:
- Die Persona Library enthält Ihre wiederverwendbaren, versionierten Personas.
- Eine Persona Group ist ein benannter Pool von Personas, den Sie für ein Experiment auswählen.
- Ein Persona-Experiment führt jede Persona der Group gegen jede Zeile einer Question Library aus — dieser Fan-out erzeugt eine simulierte Unterhaltung pro Persona und Zeile.
Quick Start¶
- Öffnen Sie Personas (in der Sidebar unter Library) und erstellen Sie mit New eine neue Persona.
- Erstellen Sie eine Persona Group und fügen Sie die Personas hinzu, die Sie gemeinsam evaluieren möchten.
- Erstellen Sie eine Persona-Collection, die einem Template folgt und schon alle nötigen Spalten beinhaltet.
- Unter Criteria Library erstellen sie ein neues Kriterien-Set.
- Optional: Gehen Sie zu Prompt Templates und erstellen Sie ein system-only-Template — den System-Prompt für Ihren Bot, der getestet wird.
- Gehen Sie zu Experiments → New Experiment und wählen Sie den Typ Persona.
- Wählen Sie Ihre Persona Group, die Collection, optional das system-message-only-Template, eine LLM-Config für den Bot und ein Criterion-Set.
- Starten Sie das Experiment. Jede Persona wird gegen jede Zeile ausgeführt, und jedes Transkript wird vom Criterion-Set bewertet.
Kernkonzepte¶
| Konzept | Beschreibung |
|---|---|
| Persona | Ein wiederverwendbarer, versionierter simulierter Nutzer. Hat einen Name, eine Persona description (Persönlichkeit und Verhalten) und optionales Domain knowledge (Hintergrundwissen des simulierten Nutzers). Description und Domain knowledge können {{column}}-Platzhalter enthalten, die aus der Zeile der Collection gefüllt werden. |
| Persona Library | Die projektweite Sammlung von Personas. Personas können organisationsweit geteilt werden (in anderen Projekten schreibgeschützt). |
| Persona Group | Ein benannter, veränderbarer Pool von Personas. Experimente referenzieren eine Group; ihre Mitglieder werden beim Start in das Experiment gepinnt. |
| Question Library | Eine Persona-Collection mit einem Szenario pro Zeile. Muss eine Persona goal-Spalte enthalten, die dem Simulator das zu verfolgende Ziel vorgibt. Andere Spalten können als {{placeholders}} in Persona-Beschreibungen referenziert werden. |
| Simulator | Das LLM, das den Nutzer spielt, gesteuert durch die Persona. Der Simulator ist eine Deployment-Level-Einstellung und nicht durch Nutzer konfigurierbar. |
| Bot/LLM-Endpoint | Das zu testende LLM oder Bot-Endpoint, welches durch die LLM-Config des Experiments definiert wird und eine optionale system-only-Prompt-Template. |
| Beendigung | Der Simulator kann ein end_conversation-Tool mit einem von drei Gründen aufrufen — goal_met, goal_failed oder stuck. Wird das Tool nie aufgerufen, endet die Schleife bei einer harten Obergrenze von MAX_TURNS = 16. |
Die Persona Library¶
Öffnen Sie Personas in der Sidebar unter Library. Die Seite ist ein zweispaltiger Workbench: links die Persona Library, rechts die Persona Groups.
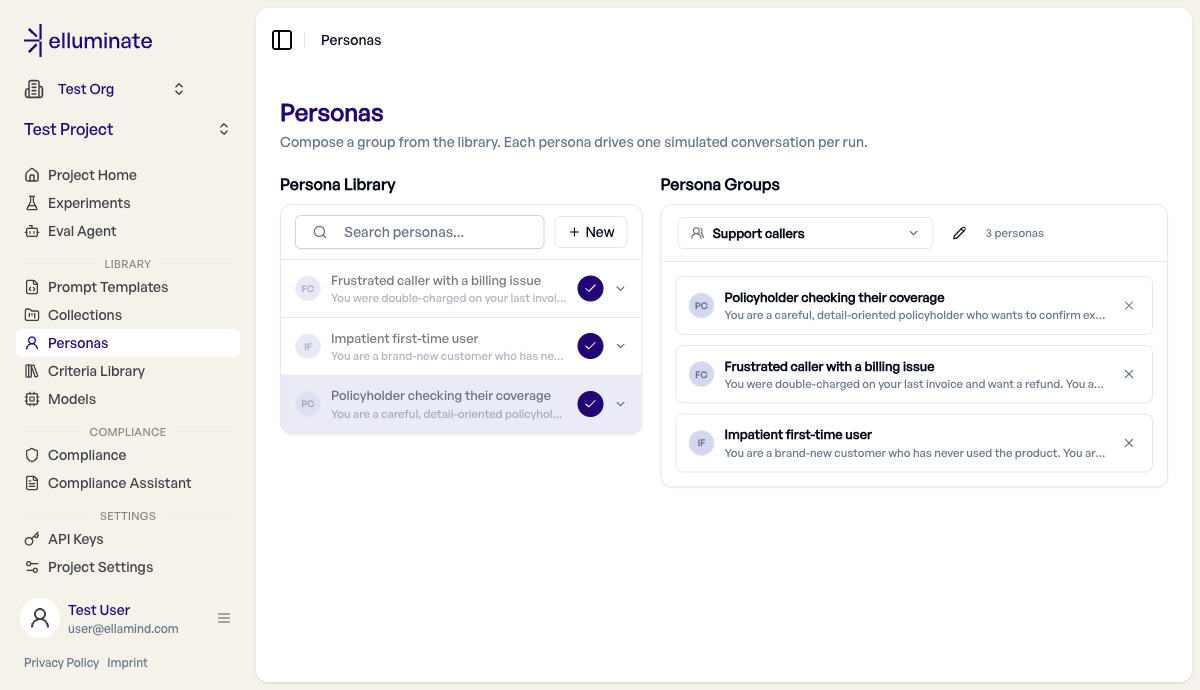
Personas erstellen und bearbeiten¶
- Klicken Sie oben in der Library auf New, um den Inline-Editor zu öffnen.
- Füllen Sie aus:
- Name — ein kurzes Label (z. B. Ungeduldiger User, der die Platform zum ersten Mal benutzt.).
- Persona description — die Persönlichkeit und das Verhalten, das der Simulator annehmen soll.
- Domain knowledge (optional) — Wissen oder Kontext, über den der simulierte Nutzer verfügt. Z.b. eine Sammlung an Versicherungsrichtlinien
- Klicken Sie auf Save. Klicken Sie später auf eine beliebige Persona-Zeile, um sie an Ort und Stelle zu bearbeiten.
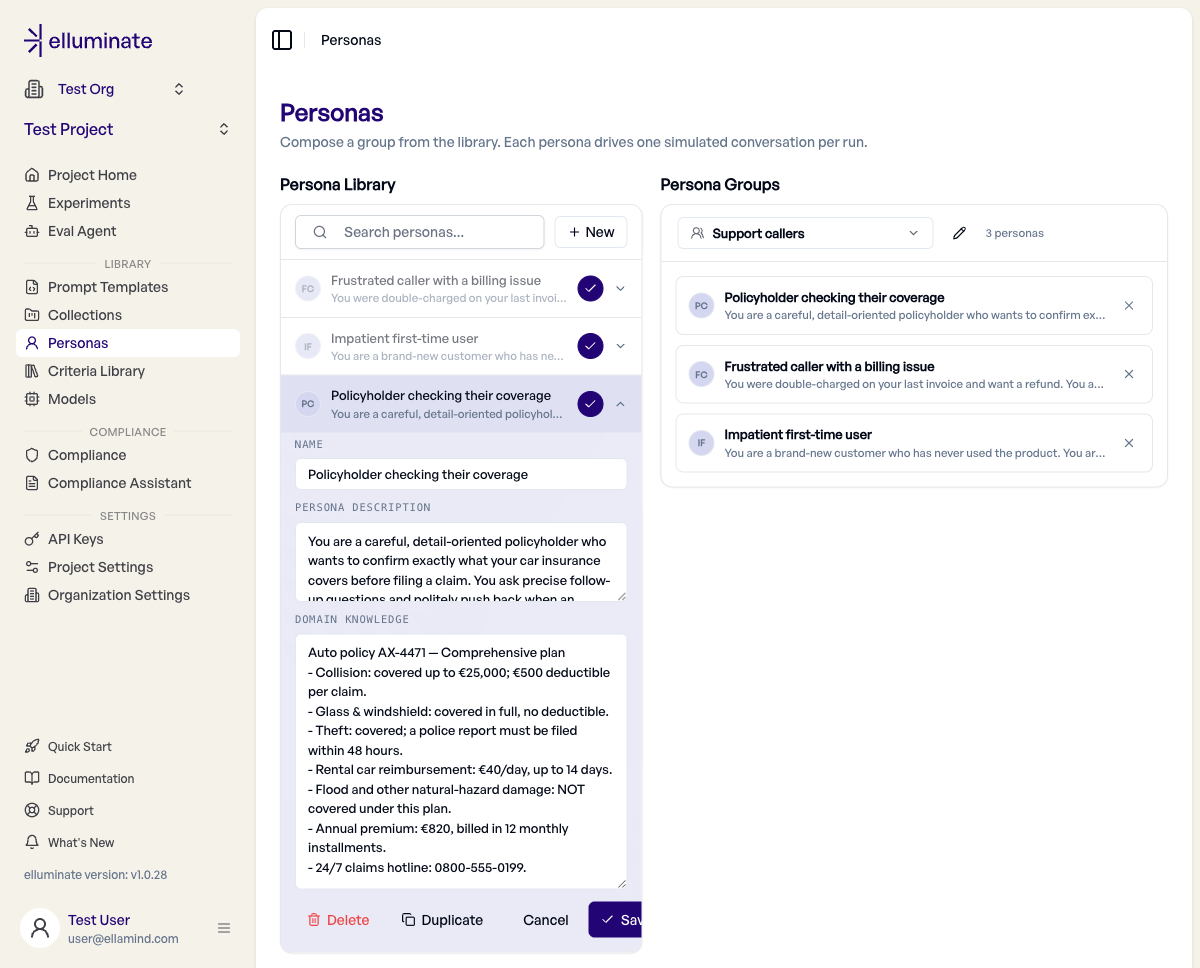
Persona Groups¶
Eine Persona Group ist ein benannter Pool von Personas, den ein Experiment gemeinsam ausführt.
- Verwenden Sie im rechten Bereich den Group-Switcher, um eine New group zu erstellen — geben Sie ihr einen Namen und optional eine Beschreibung.
- Fügen Sie Personas über die + / ✓-Schaltfläche an jeder Library-Zeile zur Group hinzu. Mitglieder erscheinen als Karten im Group-Roster.
- Entfernen Sie ein Mitglied über das ✗ auf seiner Karte.
Groups sind veränderbar und nicht versioniert. Wenn ein Experiment erstellt wird, erfasst es einen unveränderlichen Snapshot der exakten Persona-Versionen in der Group zu diesem Zeitpunkt, sodass spätere Änderungen an der Group oder ihren Personas ein abgeschlossenes Experiment nie verändern.
Die Question Library¶
Ein Persona-Experiment läuft gegen eine Question Library — eine Persona-Collection, in der jede Zeile ein Szenario ist.
- Die Collection muss eine Persona goal-Spalte enthalten. Ihr Wert ist das Ziel, das der Simulator für diese Zeile verfolgt.
- Alle anderen Spalten können als
{{placeholders}}in der Description oder dem Domain knowledge einer Persona referenziert werden. - Eine Persona-Collection lässt sich nicht mit Direkte Eingabe- oder Conversation-Spalten mischen — sie ist ein eigenständiger Collection-Typ.
Das Prompt-Template des Bots (optional)¶
Der zu testende Bot/LLM-Endpoint wird über ein system-only-Prompt-Template konfiguriert:
- Genau eine
system-Nachricht. - Keine
user- oderassistant-Nachrichten. - Keine User-seitigen Platzhalter — die User-Turns werden vom Simulator generiert.
Wenn Sie ein Persona-Experiment einrichten, wird der Template-Picker so gefiltert, dass nur system-only-Templates angezeigt werden, da an den LLM-Endpoint des Bots ausschließlich die System-Nachricht übergeben wird.
Ein Persona-Experiment ausführen¶
- Gehen Sie zu Experiments → New Experiment und wählen Sie den Typ Persona.
- Wählen Sie unter Choose a persona group die zu evaluierende Group.
- Wählen Sie die Question Library, das system-only-Prompt-Template, die LLM-Config für den zu testenden Bot und das Criterion-Set, das die Transkripte bewertet.
- Prüfen Sie die Anzahl der Unterhaltungen und starten Sie das Experiment.
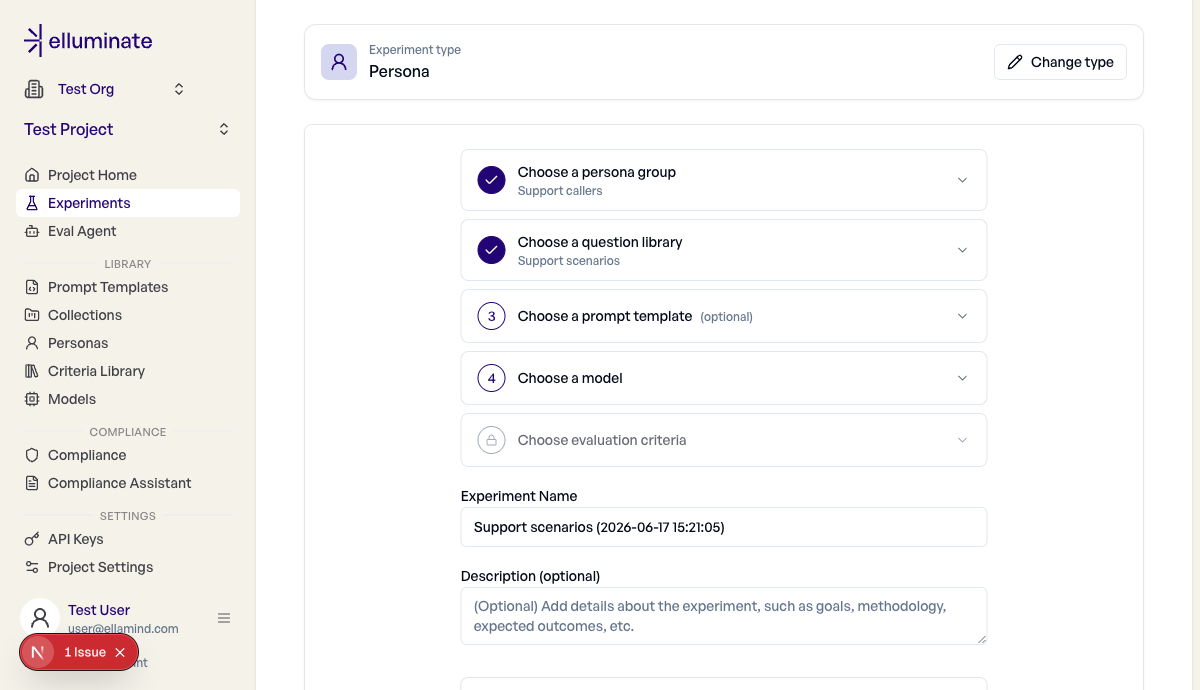
Das Experiment fächert über beide Dimensionen auf: Es führt eine Unterhaltung pro Persona und pro Question-Library-Zeile aus. Mit P Personas und R Zeilen erzeugt das Experiment P × R Unterhaltungen, was das Formular vor dem Start als Live-Zähler anzeigt.
Wie ein Run abläuft¶
Für jedes Paar aus (Persona, Question-Library-Zeile):
- Description und Domain knowledge der Persona werden gegen die
{{column}}-Werte der Zeile gerendert, und das Ziel wird aus der Persona goal-Spalte gelesen. - Der Simulator generiert die nächste User-Nachricht. Er sieht den vollständigen Gesprächsverlauf mit vertauschten Rollen (die Antworten Ihres Bots erscheinen für den Simulator als
user-Nachrichten und umgekehrt). - Basierend auf dem optionalen system-only-Prompt-Template und der LLM-Config des Experiments antwortet der Bot/LLM-Endpoint, der getestet wird.
- Die Schritte 2 und 3 wiederholen sich, bis der Simulator
end_conversationaufruft oderMAX_TURNSerreicht wird. - Das finale Transkript wird als Response gespeichert und vom Criterion-Set bewertet.
Stateless vs. stateful Provider
Die meisten Provider (OpenAI, Custom API, Mock) sind stateless: Bei jedem Bot-Turn wird der vollständige Gesprächsverlauf erneut gesendet. Botario hält Session-State serverseitig vor, identifiziert über sessionId — pro Aufruf wird daher nur der aktuelle User-Turn gesendet. Botario verwirft zudem stillschweigend den System-Prompt des Bots, da der State auf der Botario-Seite liegt. Der System-Prompt bleibt im gespeicherten Transkript erhalten, wird aber nicht an den Bot gesendet.
Ergebnisse lesen¶
- Der vollständige Dialog zwischen Simulator und Bot wird auf jeder Response gespeichert und ist im Response-Viewer sichtbar.
- Criterion-Bewertungen beziehen sich auf das gesamte Transkript, nicht auf einen einzelnen Turn.
- Der Beendigungsgrund (
goal_met,goal_failed,stuckoderMAX_TURNS) wird auf der Response ausgewiesen. - Da jede Response mit der Persona verknüpft ist, die sie erzeugt hat, können Sie Ergebnisse nach Persona filtern, um zu vergleichen, wie unterschiedliche Personas bei denselben Szenarien abgeschnitten haben.
SDK-Referenz¶
Personas und Persona Groups werden in der UI verwaltet. Das SDK kann beim Start eines Multi-Turn-Experiments eine bestehende Persona Group referenzieren, indem es deren persona_group_id übergibt, die für MULTI_TURN-Experimente erforderlich ist:
from elluminate import Client
client = Client()
experiment, _ = client.experiments.get_or_create(
name="Support quality — multi-turn",
collection=question_library, # eine Persona-Collection
prompt_template=system_only_template,
persona_group_id=group_id, # für MULTI_TURN erforderlich
)
Personas über das SDK verwalten
Das SDK erstellt oder bearbeitet keine Personas oder Persona Groups — legen Sie diese zuerst in der UI an und referenzieren Sie dann die ID der Group. persona_group_id ist auf experiments.create, experiments.get_or_create und ihren async-Äquivalenten verfügbar.
Verwandte Themen¶
- Konversationen — statische, vorab aufgezeichnete Gesprächsverläufe
- Agentic Evaluations — Evaluationen tool-nutzender Agenten
- Criterion Sets — Regel-Collections zur Bewertung von Transkripten
- Experimente — Evaluationen Ende-zu-Ende ausführen