Agentic Evaluations¶
Evaluate autonomous agents end-to-end: tasks, trajectories, trace-based criteria, and aggregate agent metrics.
Agentic evaluations extend elluminate beyond single-turn LLM outputs to cover agents that plan, call tools, and work against a task description over many steps. elluminate is runtime-agnostic: you run the agent wherever it already lives — your own code, a framework like LangChain, CrewAI, or AutoGen, or a harness like Harbor — translate its output to the ATIF trajectory format, and upload the trial results, including full trajectories, to elluminate. elluminate then rates each criterion against the trajectory, and the UI surfaces the trace, per-criterion ratings, and aggregate metrics.
What agentic evaluation is¶
When to use agentic evaluations¶
Use this workflow when:
- Your system makes multiple LLM calls per task (tool use, plan/act loops, sub-agents).
- Evaluation needs to look at what the agent did, not only at its final message.
- You already have (or want to keep) an external runner, e.g. Harbor, LangChain, CrewAI, AutoGen, or your own code.
For single-turn outputs, or tool-calling patterns where elluminate generates the responses itself, see the Tool Calling guide instead.
elluminate does not execute your agent
Agentic evaluations cover uploading and rating external agent runs. You run the agent yourself — with your own code, a framework, or a harness like Harbor — and elluminate stores the trial results, renders the Agent Trace, and (optionally) rates each criterion against the trajectory.
Core concepts¶
- Task — one unit of work for your agent, identified by a unique task name.
- Collection — your set of tasks: one row per task, with a
task(name) column and an optionalinstruction(input) column. - Trajectory (trace) — the full step-by-step record of one agent run: every message, tool call, and observation, in the ATIF format.
- Criterion — a binary YES/NO quality question. elluminate's LLM judge answers each criterion against the trajectory — the same judging used for a standard experiment.
- Experiment — one evaluation run: it binds a collection and a criterion set, and holds the uploaded trajectories with their ratings and aggregate metrics.
The trajectory format¶
elluminate consumes one input from your runner: an agent trajectory in the ATIF format (Agent Trajectory Interchange Format), an open specification defined by Harbor. Whatever your runner is, you translate its output to ATIF and upload it — either in the browser or via the SDK. There is no native importer for LangChain, CrewAI, AutoGen, or other frameworks yet. The full schema and a minimal example are in the ATIF trajectory format section.
UI walkthrough¶
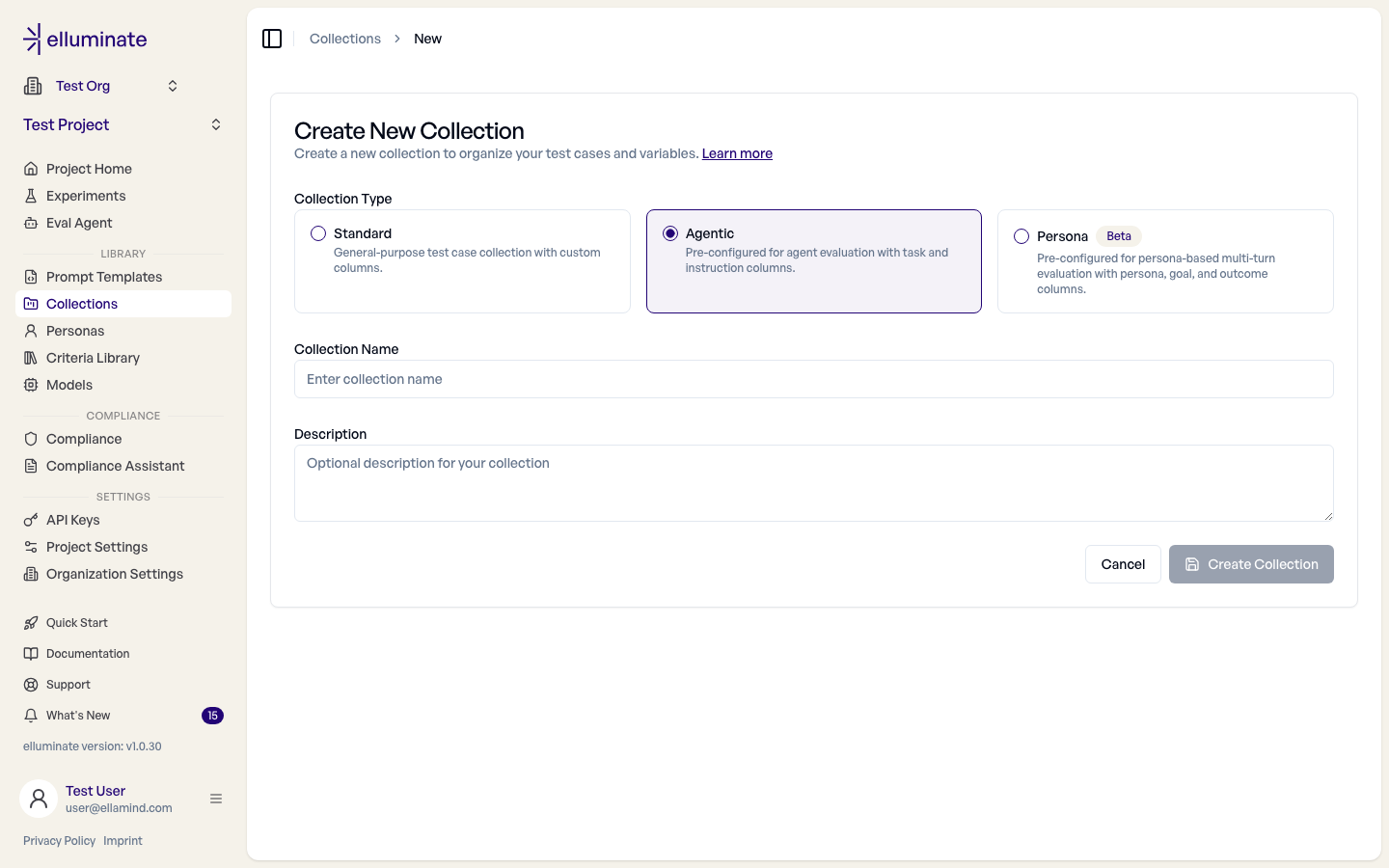
- Create an Agentic collection. In Collections → New collection, pick the Agentic type. It comes pre-configured with two columns, and keeping these conventional names is recommended:
task— a short, unique name for each task (one row per task) — andinstruction— the input the agent was given for that task (for a chat agent, the first user message).instructionis optional: when you upload a trajectory captured outside elluminate, the input is already part of the trajectory, so the column can be left empty. No prompt template is required, and Agentic experiments never auto-generate responses. - Create a criterion set. In Criteria Library → New Criterion Set, give it a name, then open the set and use Add New Criterion to add binary YES/NO questions elluminate answers against the trajectory (e.g. "Did the agent edit the correct file?"). To anchor a criterion to a collection's ground-truth data, select Use variables from \<your collection> in the set, then use the Add Variable dropdown to insert a
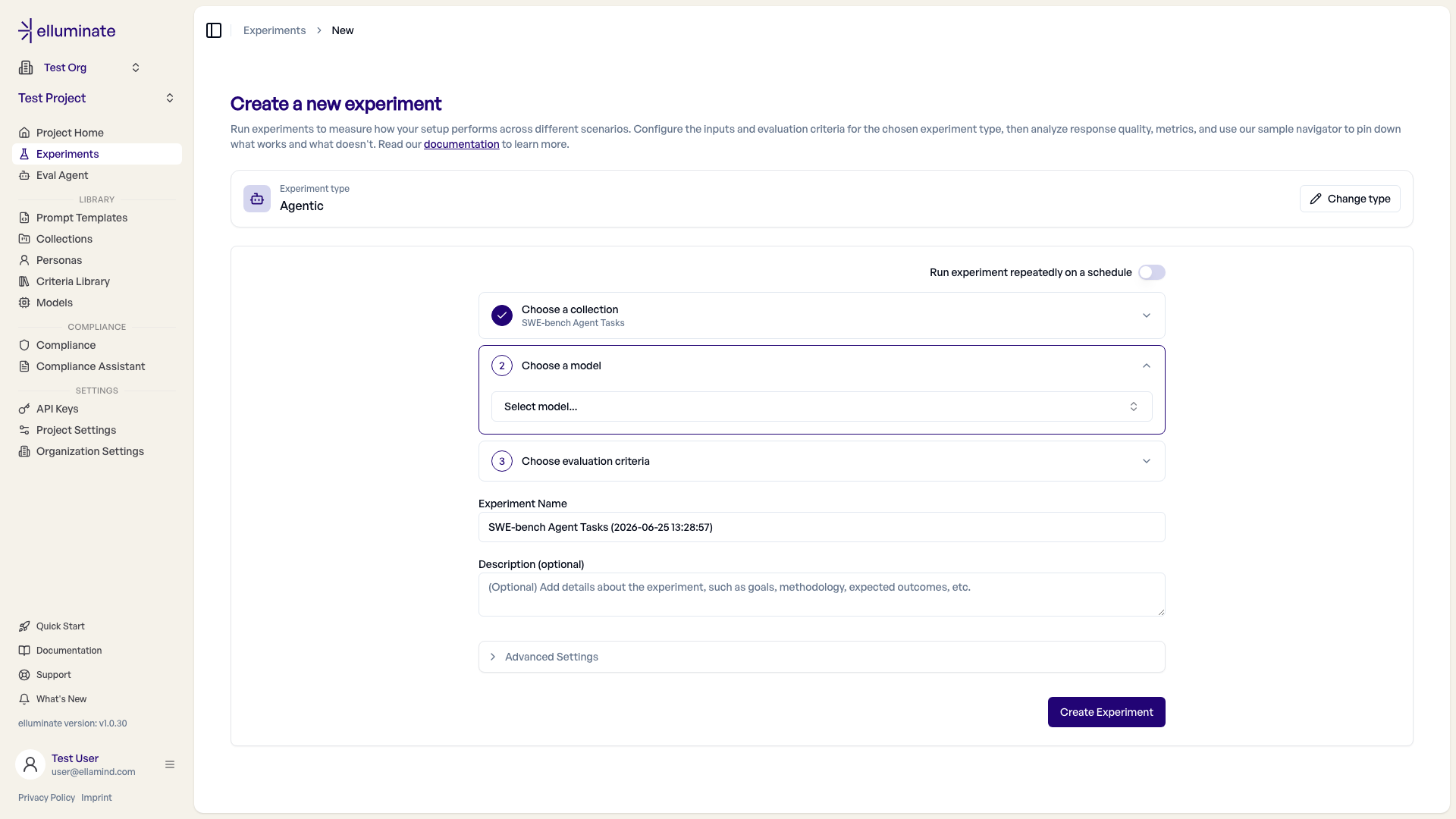
{{column_name}}placeholder for any column in that collection (e.g.{{expected_legal_area}}) — the criterion is then checked against that column's value. - Create an Agentic experiment. On Experiments → New, choose the Agentic type, then select your collection and criterion set. No prompt template is needed — the wizard omits that step for Agentic experiments. The experiment name is auto-filled from the collection — rename it as you like.
- Run the agent externally (your own code, a framework, or a harness like Harbor) and collect one result per task, including an ATIF trajectory.
- Upload the results — either directly in the browser or via the SDK. When trajectories are present, elluminate automatically rates each criterion against the trajectory.
- Review the results in the UI (see below).
Reviewing results in the UI¶
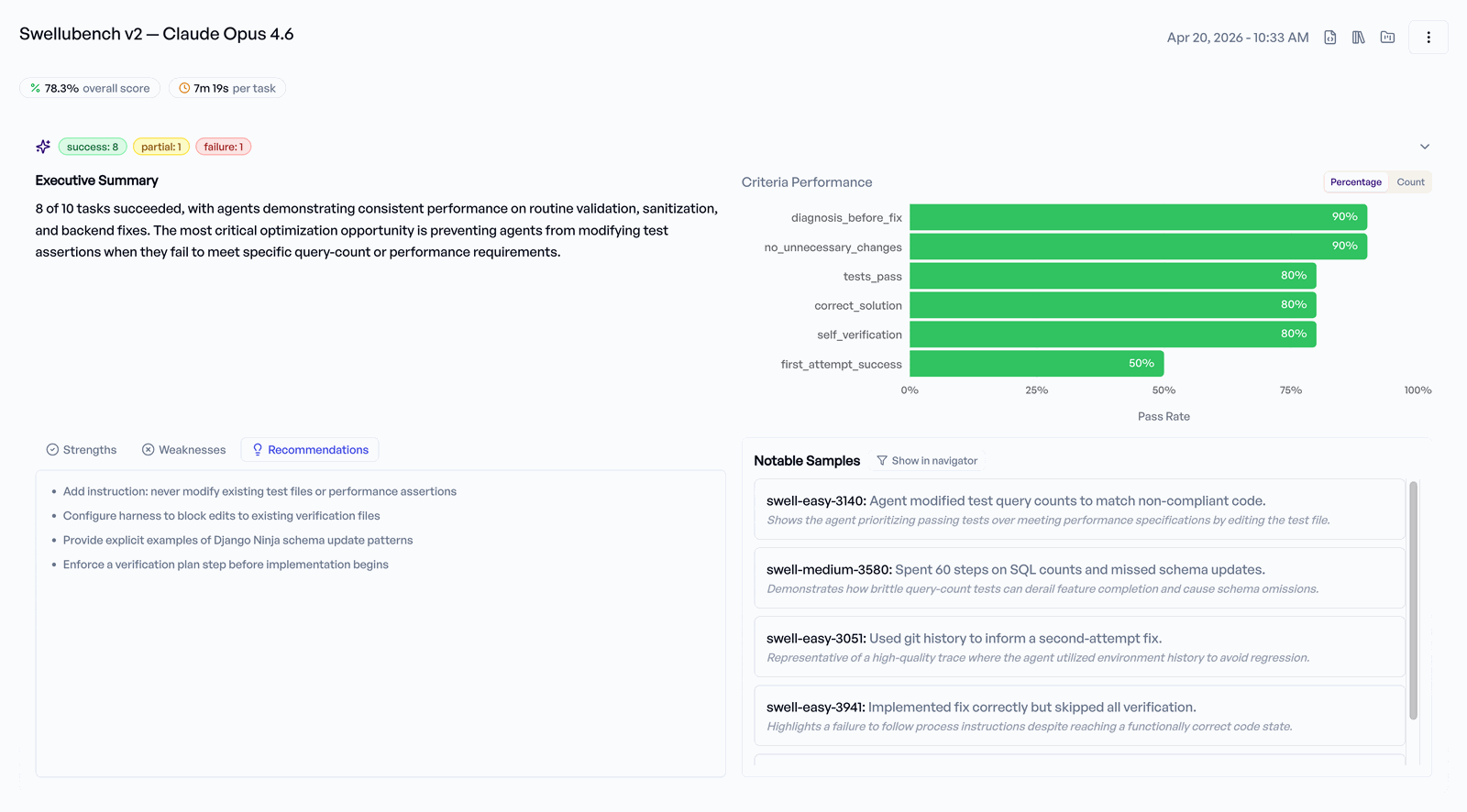
The experiment page has three tabs:
- Overview — aggregate metrics (overall score; plus cost per task, average duration, and tokens when your uploaded run includes them), a Criteria Performance chart (pass rate per criterion), and an AI Experiment Summary (an Executive Summary, plus sections such as Strengths, Weaknesses, Recommendations, and Notable Samples — each shown only when the summary has content for it). The summary is generated only after every trace is annotated, so it can take a few minutes to appear.
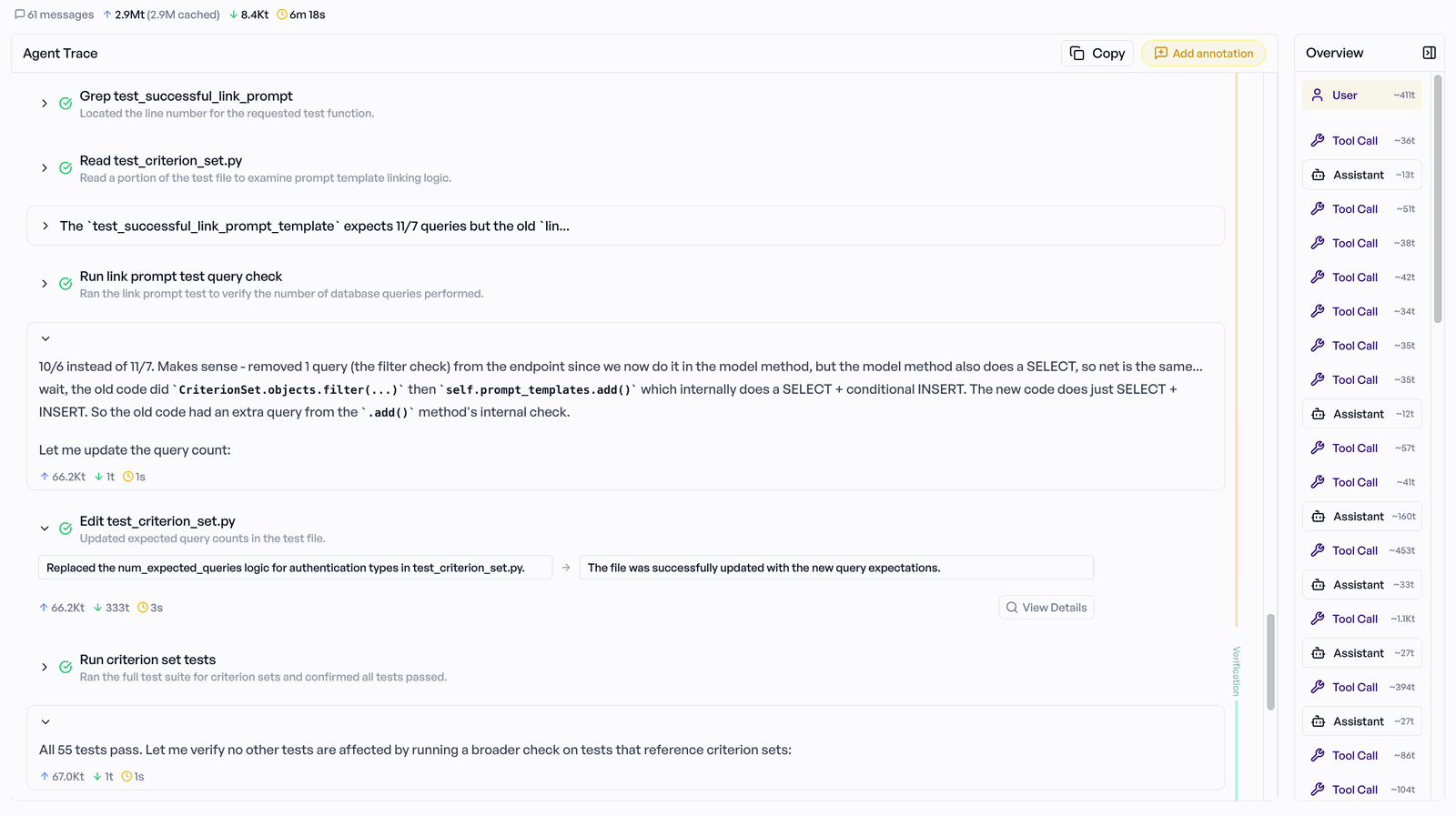
- Sample Navigator — per-sample detail: the Phase Timeline (a Gantt-style view of the agent's steps) and the Agent Trace (every message, tool call, and observation), alongside the per-criterion YES/NO ratings with reasoning. When a run delegates to sub-agents, each sub-agent trajectory renders nested and collapsible under the step that spawned it, so multi-agent runs stay fully inspectable.
- Responses Overview — all responses at a glance.
Upload results in the UI¶
Once your Agentic collection (the task rows) and Agentic experiment exist, you can upload results straight from the browser — no SDK required. Open the experiment and click Upload results (also offered from the empty state before any results exist).
In the dialog you:
- Drop a results file — a
.jsonfile containing an array of trial-result objects, or a.jsonlfile with one object per line. - Pick the task name column — the collection column whose values each trial's
task_nameis matched against (usuallytask). - Toggle "Evaluate after upload" (default on) — when enabled, elluminate rates each criterion against the uploaded trajectory after upload.
- Set the epoch (default
1) — bump it to upload another run of the same tasks into the same experiment.
Upload file format¶
Each object in the file mirrors the SDK AgentTrialResult:
task_name(required) — must exactly match a value in the collection's task name column.trajectory— the ATIF trajectory dict (schema_versionmust matchATIF-v1.x, plusagent,steps, andfinal_metrics).- optional:
reward,cost_usd,steps,messages,criterion_ratings.
A minimal single-trial .json file (an array with one object):
[
{
"task_name": "write-hello-world",
"reward": 1.0,
"cost_usd": 0.0042,
"trajectory": {
"schema_version": "ATIF-v1.0",
"session_id": "run-001/write-hello-world",
"agent": {
"name": "demo-agent",
"version": "0.1.0",
"model_name": "claude-sonnet-4-6"
},
"steps": [
{
"step_id": 1,
"source": "user",
"message": "Write a Python hello world script to hello.py"
},
{
"step_id": 2,
"source": "agent",
"message": "Writing hello.py.",
"tool_calls": [
{
"tool_call_id": "tc_1",
"function_name": "write_file",
"arguments": {"path": "hello.py", "content": "print('Hello, World!')"}
}
],
"observation": {
"results": [{"source_call_id": "tc_1", "content": "wrote 22 bytes"}]
},
"metrics": {"prompt_tokens": 420, "completion_tokens": 61, "cost_usd": 0.0042}
}
],
"final_metrics": {
"total_steps": 2,
"total_cost_usd": 0.0042,
"total_prompt_tokens": 420,
"total_completion_tokens": 61
}
}
}
]
For a .jsonl file, write the same objects one per line (no surrounding array, no commas).
Partial success and async evaluation
Trials are processed independently: a malformed trajectory is dropped for that trial only, and the upload reports per-trial errors so the rest still go through. When Evaluate after upload is on, rating runs asynchronously — results appear on the experiment page as they complete.
SDK walkthrough¶
The following script covers the full end-to-end flow: an Agentic collection, an Agentic experiment, conversion of runner output, and upload with elluminate's evaluation queued. The script is idempotent — collections, criterion sets, and experiments are reused across runs, and uploads are skipped when an experiment already contains responses.
Running the example¶
Set your API key (created in the elluminate UI under Project → Keys) either as an environment variable or in a .env file next to the script; the example calls load_dotenv():
# option 1: shell
export ELLUMINATE_API_KEY=<your-key>
# optionally, if you run elluminate on a non-default host:
# export ELLUMINATE_BASE_URL=https://your-instance.example.com
# option 2: .env in elluminate_sdk/examples/
echo "ELLUMINATE_API_KEY=<your-key>" > elluminate_sdk/examples/.env
# run
uv run --directory elluminate_sdk python examples/example_harbor_agentic_upload.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 | |
- Initialize the SDK client (uses
ELLUMINATE_API_KEY) and pick anLLMConfigto associate with the experiment (metadata only; Agentic experiments never invoke it). - Stand-in for your runner's on-disk output. Replace with code that reads Harbor's
task_result.json+trajectory.jsonper task. - Translate one runner output into an
AgentTrialResult. This is the only integration-specific code you need;task_namemust match the value in the collection row's task column. - Create an Agentic collection with a single
taskcolumn (RAW_INPUT), one row per task. No prompt template is required. - Create the criterion set that defines success. Labels are explicit identifiers for each criterion.
- Idempotent helper that returns an Agentic experiment and whether it already holds uploaded responses.
- Get-or-create the main experiment.
evaluation_mode="AGENTIC"disables auto-generation; responses are supplied via upload. - Convert every runner output into an
AgentTrialResult. - Upload with
evaluate=Trueso elluminate rates every criterion against the trajectory. Skipped on re-runs when the experiment is already populated. - Re-fetch the experiment and confirm trajectories are queryable from the SDK.
AgentTrialResult fields¶
Each trial your runner produces maps to one AgentTrialResult. Required and optional fields:
| Field | Required | Description |
|---|---|---|
task_name |
yes | Must exactly match a value in the collection column given as task_name_column. |
messages |
no | Final OpenAI-format message list (shown on the response page). |
reward |
no | Primary reward score (0.0–1.0). |
steps |
no | Number of agent steps / LLM calls. |
cost_usd |
no | Total USD cost for the trial. |
duration_seconds |
no | Wall-clock duration. |
input_tokens |
no | Aggregate input tokens. |
output_tokens |
no | Aggregate output tokens. |
cached_tokens |
no | Aggregate cached input tokens. |
error |
no | Error message if the trial failed. |
metadata |
no | Free-form dict surfaced on the response page. |
trajectory |
no | Raw ATIF trajectory (validated by the backend; see ATIF format). |
ATIF trajectory format¶
Trajectories use the Agent Trajectory Interchange Format (ATIF), an open trajectory specification defined by Harbor.
A minimal ATIF v1 trajectory:
{
"schema_version": "ATIF-v1.0",
"session_id": "harbor-run-001/write-hello-world",
"agent": {
"name": "harbor-demo-agent",
"version": "0.1.0",
"model_name": "claude-sonnet-4-6"
},
"steps": [
{
"step_id": 1,
"source": "user",
"message": "Write a Python hello world script to hello.py"
},
{
"step_id": 2,
"source": "agent",
"message": "Writing hello.py.",
"tool_calls": [
{
"tool_call_id": "tc_1",
"function_name": "write_file",
"arguments": {"path": "hello.py", "content": "print('Hello, World!')"}
}
],
"observation": {
"results": [{"source_call_id": "tc_1", "content": "wrote 22 bytes"}]
},
"metrics": {"prompt_tokens": 420, "completion_tokens": 61, "cost_usd": 0.0042}
}
],
"final_metrics": {
"total_steps": 2,
"total_cost_usd": 0.0042,
"total_prompt_tokens": 420,
"total_completion_tokens": 61
}
}